MENU
Full Program
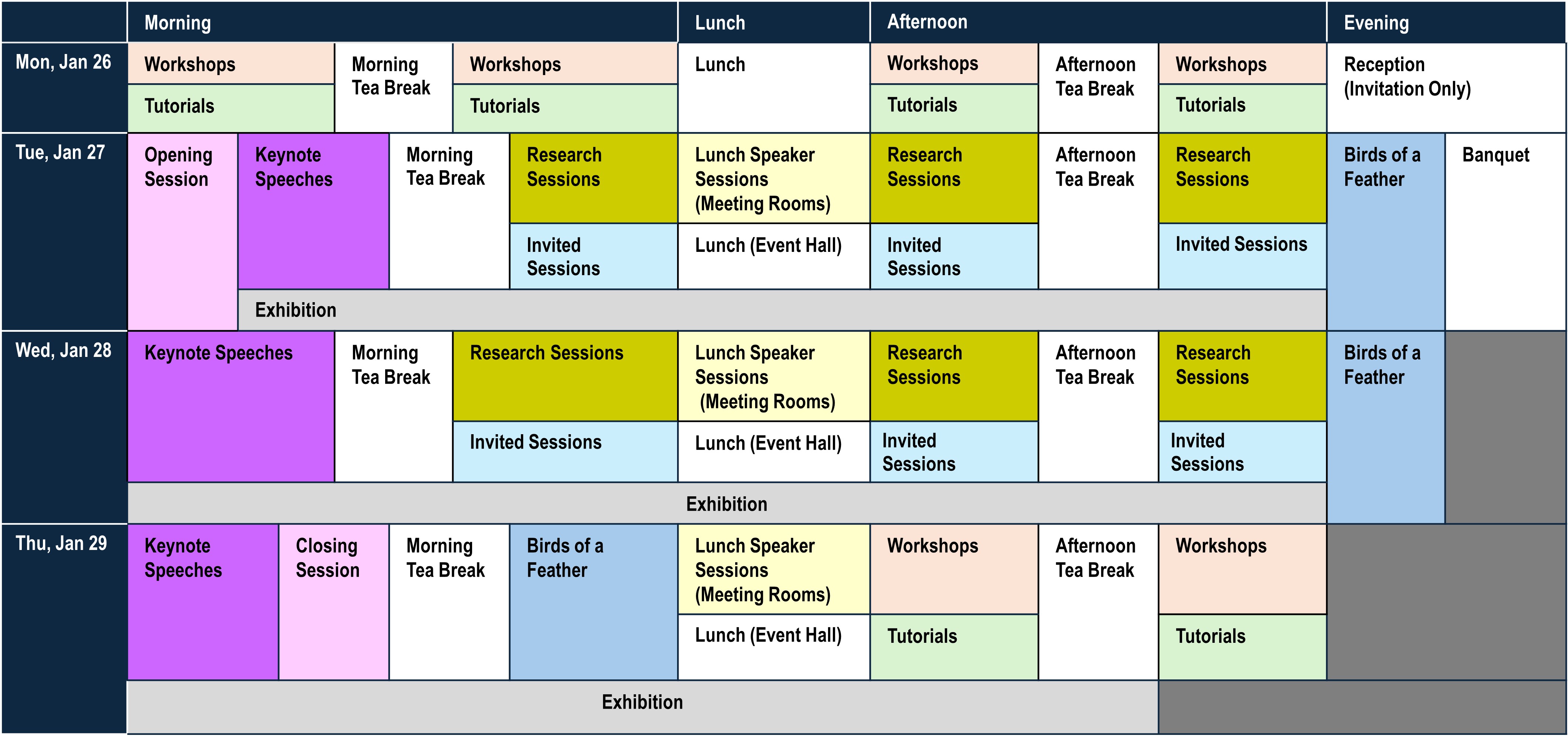
NOTE: The program is frequently updated, and all dates, times, and room information are subject to change.
- January 26 (Mon)
- January 27 (Tue)
- January 28 (Wed)
- January 29 (Thu)
Full Day
Mon, January 26, 2026 9:30 - 16:30 Room 803
Contributors: Kazuya Yamazaki, Jack Wells, Jeff Larkin
Abstract: This workshop brings together OpenACC users from national laboratories, universities, industry, and other research institutions to exchange information and share the OpenACC programming model's uses in various science domains. A directive-based and performance-portable parallel programming model designed to program many types of accelerators, OpenACC is compatible with the C, C++, and Fortran programming languages. OpenACC simplifies the process of porting codes from host devices to various high-performance computing accelerators, significantly reducing the time and effort scientists and engineers spend programming. One may also think of OpenACC as user- specified directives that fill gaps in the standard programming languages. As standard parallel programming languages mature, one will expect that program developers will have fewer gaps to fill. This vision is consistent with greater portability and sustainability of scientific programming over time. Indeed, features pioneered in OpenACC are informing the development work of official ISO standard programming models. We are planning presentations from users of OpenACC and panel discussions of topics of interest to the community, highlighting forefront research applications in a variety of research domains and discussions of the future evolution of the OpenACC standard.
Website: OpenACC User Workshop at SCA2026
Program:
- 09:30-09:35
- Welcome and Introduction
- Kazuya Yamazaki, Jack Wells, Jeff Larkin (The University of Tokyo, NVIDIA, NVIDIA)
- 09:35-09:45
- OpenACC Specification Update
- Jeff Larkin (OpenACC Technical Chair)
- 09:45-10:20
- Compiler Updates (GCC, NVIDIA, HPE)
- Thomas Schwinge, Kazuaki Matsumura, David Oehmke (BayLibre, NVIDIA, HPE)
- 10:20-10:45
- OpenACC-based GPU acceleration for the SCALE atmospheric model: status and challenges
- Seiya Nishizawa (RIKEN)
- 10:45-11:15
- Break
- 11:15-11:35
- Optimization of the SCALE atmospheric model customized for super-parameterization
- Kazuya Yamazaki (The University of Tokyo)
- 11:35-12:05
- Governmental support for GPU-ization on HPC/AI applications toward Fugaku-NEXT and nation-wide GPU systems
- Taisuke Boku (Director, Advanced HPC-AI Research and Development Support Center, RIST / Center for Computational Sciences, University of Tsukuba)
- 12:05-12:30
- Solomon: unified schemes for directive-based GPU offloading
- Yohei Miki (The University of Tokyo)
- 12:30-13:30
- Lunch Break
- 13:30-13:55
- GPU optimization of the Japanese high-resolution atmospheric model NICAM with OpenACC
- Hisashi Yashiro (National Institute for Environmental Studies, Japan)
- 13:55-14:20
- An OpenACC-Based Implementation of Lattice H-Matrix–Vector Multiplication on GPU Clusters
- Tetsuya Hoshino (Nagoya University)
- 14:20-14:45
- GPU Acceleration and Performance Optimization of a High-Order Combustion Solver LS-FLOW-HO Using OpenACC
- Osamu Watanabe (Japan Aerospace Exploration Agency)
- 14:45-15:15
- Break
- 15:15-15:40
- Using OpenACC for Scientific Applications
- Sunita Chandrasekaran (University of Delaware)
- 15:40-16:05
- GPU-Accelerated Particle Tracing on Unstructured Meshes Using OpenACC
- Chun-Sung Jao (National Center for High-performance Computing, Taiwan)
- 16:05-16:20
- Discussions
- 16:20-16:30
- Workshop Concludes/Closing remarks
- Kazuya Yamazaki, Jack Wells, Jeff Larkin (The University of Tokyo, NVIDIA, NVIDIA)
Mon, January 26, 2026 9:30 - 16:30 12F Grand Toque
Contributors: Ikko Hamamura, Ryousei Takano, Pascal Jahan Elahi, Tommaso Macrì, Nan-yow Chen, Yun-Yuan (Pika) Wang
Abstract: The workshop *“Accelerated Quantum Supercomputing: CUDA-Q Connects HPC, Quantum, and Applications”* is a dedicated event focused on the integration of quantum computing within high-performance computing (HPC) ecosystems. Bringing together experts from HPC, quantum software, hardware, and various application domains, the program explores technical milestones and the ongoing challenges of *hybrid HPC–quantum systems*.
Key themes include distributed quantum computing, scalable architectures, and GPU simulation. The workshop balances theoretical insights with practical application, featuring a *hands-on session* with state-of-the-art quantum devices and simulators. Real-world use cases in *chemistry, optimization, and machine learning* will be showcased to demonstrate the tangible impact of quantum acceleration across scientific and industrial sectors.
By facilitating interdisciplinary dialogue, the workshop aims to *explore potential breakthroughs and discuss future directions* for scalable quantum supercomputing. Participants will gain a holistic view of the current landscape and emerging trends, fostering connections between quantum software development and HPC infrastructure. Attendees will *leave with valuable insights and practical perspectives* to contribute to the evolving field of quantum-accelerated high-performance computing.
Website: https://sites.google.com/view/sca-hpcasia2026-quantum
Program:
- 09:30-09:35
- Opening Remarks
- Ikko Hamamura (NVIDIA)
- 09:35-09:55
- ABCI-Q: Quantum-AI Hybrid Computing Information
- Ryousei Takano (AIST)
- 09:55-10:20
- Enabling GPU-Accelerated Pulse-Level QPU Emulation in Qibolab via CUDA-Q Dynamics
- Khoo Jun Yong (A*STAR)
- 10:20-10:45
- Distributed Quantum Optimization and Machine Learning in Quantum-HPC Ecosystem
- Kuan-Cheng Chen (Jij Europe/Imperial College London)
- 10:45-11:15
- Break
- 11:15-11:40
- Toward practical quantum-classical hybrid application
- Shinji Kikuchi (Fujitsu)
- 11:40-12:05
- Hybrid HPC–Quantum Workflows in Practice
- Juan Pedersen (Quantinuum)
- 12:05-12:30
- Lessons learned from real HPC+QC Integration
- Eric Mansfield (IQM)
- 12:30-13:30
- Lunch
- 13:30-14:45
- Pawsey Quantum Supercomputing Innovation Hub and Hybrid Quantum Computing
- Pascal Jahan Elahi and Tommaso Macrì (Pawsey and QuEra)
- 14:45-15:15
- Break
- 15:15-15:40
- Efficient Tensor Network Simulation of Large-Scale Quantum Circuits on HPC Systems
- Tai-Yue Li (NCHC)
- 15:40-16:05
- Recent progress in quantum algorithms for quantum chemistry
- Masaya Kohda (QunaSys)
- 16:05-16:30
- Qamomile and SQOA-QR for Sampling-Based Hybrid Quantum Optimization
- Yu Yamashiro (Jij)
Mon, January 26, 2026 9:30 - 16:30 Room 1202
Contributors: Michael Ott, Ayesha Afzal, Fumiyoshi Shoji, Natalie Bates
Abstract: As the performance, power, and heat density of supercomputers continues to grow — driven by the integration of high-power heterogeneous components such as multi-core CPUs, GPUs, high-bandwidth memory, and high bandwidth interconnects — coordinated strategies across facilities, utilities, HPC systems, and applications are required to manage energy use, reduce environmental impact, and ensure long-term operational viability.
The Energy Efficient HPC State of the Practice workshop will focus on the operational, infrastructural, and environmental challenges of deploying and managing modern high-performance computing systems. The primary objective of this workshop is to capture and disseminate best practices, case studies, and reproducible operational experiences from HPC centers, facilities, and vendors worldwide.
While energy efficiency has long been recognized as a critical constraint, sustainability metrics such as greenhouse gas (GHG) emissions, embodied carbon, and water consumption are now also coming into focus. This workshop will explore how to address these challenges across the full lifecycle of HPC systems — from design and manufacturing through daily operations, reuse, and decommissioning.
This year’s workshop also broadens its lens to consider AI infrastructure, which increasingly mirrors HPC in system architecture and operational demands. There are lessons to be learned from the HPC community that should help with the operation of Megawatt-scale AI racks, warm-water cooling, and hyperscale deployments. The convergence of these domains presents an opportunity to align practices, metrics, and innovations in service of a shared future where performance and sustainability must coexist.
Website: https://sites.google.com/lbl.gov/energy-efficient-hpc-sop-works/home
Call for Papers: https://sites.google.com/lbl.gov/energy-efficient-hpc-sop-works/call-for-papers
Program:
- 09:30-09:35
- Welcome and Introduction
- Michael Ott (LRZ)
- 09:35-10:20
- Designing and operating a sustainable Supercomputing Infrastructure: Lessons from CINES, a French National center, and the Adastra System (Keynote)
- Gabriel Hautreux (CINES)
- 10:20-10:45
- Providing Thermal Stability for an Exascale Supercomputer: A Case Study of Frontier’s Cooling System
- Grant, Martinez, Bortot, Grant, DePrater (Oak Ridge National Laboratory, Sandia National Laboratory, ENI, Queens University, Lawrence Livermore National Laboratory)
- 10:45-11:15
- Break
- 11:15-11:40
- Quantifying the Economic Potential of Energy-Aware Scheduling in HPC
- Menear, Donson, DiMont, Strelka, Clark, Slovensky (NREL)
- 11:40-12:05
- Co-Design of a Power State-Aware Scheduler and an Intelligent Power Manager for Energy-Efficient HPC Systems
- Prasasta, Pradata, Santiyuda, Amrizal, Pulungan, Takizawa (Universitas Ahmad Dahlan, Universitas Gadjah Mada, Institut Bisnis dan Teknologi Indonesia, Tohoku University)
- 12:05-12:30
- Combining System- and User-Level Approaches to Improving Energy Efficiency in GPU-Based Supercomputers
- Yoshida, Yamaki, Honda, Sato, Miwa (RIKEN R-CCS, The University of Electro-Communications)
- 12:30-13:30
- Lunch
- 13:30-13:55
- System-Level Energy Profiling of Wafer-Scale AI Systems: Characterizing Non-Accelerator Overheads in the Cerebras CS-2 System
- John, Mak, Hoffmann, Zhang, Patki, Hammer (LRZ, Cerebras Systems, LLNL)
- 13:55-14:20
- Harvesting energy consumption on European HPC systems: Sharing Experience from the CEEC project
- Kulkarni, Kemmler, Schwartz, Gedik, Chen, Papageorgiou, Kavroulakis, Iakymchuk (Friedrich-Alexander-University, University of Stuttgart, Umeå University, Aristotle University of Thessaloniki)
- 14:20-14:45
- On the Challenges of Energy-Efficiency Analysis in HPC Systems: Evaluating Synthetic Benchmarks and Gromacs
- Ravedutti Lucio Machado, Eitzinger, Hager, Wellein (Erlangen National High Performance Computing Center)
- 14:45-15:15
- Break
- 15:15-15:40
- Leveraging NVML GPM for NVIDIA GPU Monitoring
- Wassermann, Dollenbacher, Terboven, Müller (RWTH Aachen University)
- 15:40-16:25
- Panel: Operational Data Analytics
- Brandt, Frings, Shoga, Yamamoto (Sandia National Labs, Jülich Supercomputing Centre, Lawrence Livermore National Lab, RIKEN)
- 16:25-16:30
- Closing
- Natalie Bates (EE HPC WG)
Mon, January 26, 2026 9:30 - 16:30 Room 701 Room 1203
Contributors: Mehmet E. Belviranli, Seyong Lee, Keita Teranish, Ali Akoglu
Abstract: Recent trends toward the end of Dennard scaling and Moore’s law makes
the current and upcoming computing systems more specialized and complex,
consisting of more complex and heterogeneous architectures in terms of
processors, memory hierarchies, on-chip-interconnection networks,
storage, etc. This trend materialized in the mobile and embedded market,
and it is entering the enterprise, cloud computing, and high performance
computing markets.
RSDHA is a forum for researchers and engineers in both HPC domain and
embedded/mobile computing domain to gather together and discuss (1) the
latest ideas and lessons learned from the previous experience on
traditional (i.e., horizontal) and heterogeneity-based (i.e., vertical)
scaling in their own domains and (2) possible synergistic approach and
interaction between the two domains to find a good balance between
programmability and performance portability across diverse ranges of
heterogeneous systems from mobile to HPC.
Website: https://hpss.mines.edu/rsdha-26/
Call for Papers: https://hpss.mines.edu/rsdha-26/cfp.html
Program:
- 09:30-09:35
- Opening Remarks
- Keita Teranishi (Oak Ridge National Laboratory)
- 09:35-10:45
- [Keynote 1] Programming models for HPC-GPU-QPU hybrid computing
- Mitsuhisa Sato(RIKEN)
- 10:45-11:15
- Break
- 11:15-12:30
- Panel Session
- Jaejin Lee (Seoul National University), Kentaro Sano (RIKEN), Franz Franchetti (Carnegie Mellon University), Ryohei KOBAYASHI (Institute of Science Tokyo)
- 12:30-13:30
- Lunch
- 13:30-14:08
- [Paper Presentation 1] Distributed Runtime Support for Portable and Scalable Execution of Heterogeneous Applications
- Furkan Ozdemir and Ismail Akturk (Ozyegin University)
- 14:08-14:45
- [Paper Presentation 2] Adaptive Approximation-Aware Scheduling for Heterogeneous Computing Using Reinforcement Learning
- Ezgi Nur Alisan and Ismail Akturk (Ozyegin University)
- 14:45-15:15
- Break
- 15:15-16:25
- [Keynote 2] Exploring the Alternative Computing Landscape: Post-Turing Paradigms for Next-Generation HPC
- Omri Wolf (LightSolver)
- 16:25-16:30
- Closing Remarks
- Keita Teranishi (Oak Ridge National Laboratory)
This session has been cancelled due to unavoidable circumstances.
Mon, January 26, 2026 9:30 - 16:30 Room 802
Contributors: Benoit Martin, Jacques Morice, Julian Auriac, and Yushan Wang
Abstract: As HPC simulations scale toward exascale, I/O becomes a critical bottleneck due to the growing disparity between compute performance and storage bandwidth. Traditional post-hoc output models struggle with the volume and velocity of generated data. The Parallel Data Interface (PDI) offers a lightweight and flexible solution by decoupling I/O, filtering, and analysis logic from the simulation code. Through a declarative configuration system and a plugin-based architecture, PDI enables simulation developers to expose data buffers and trigger events without embedding I/O decisions directly into their application. PDI offers a simple API in C/C++, Fortran, and Python.
This full-day tutorial introduces PDI and its ecosystem of plugins: sequential and parallel HDF5 for file output, user-code and pycall for in-process custom logic execution, DEISA for in situ analytics, and Catalyst for live ParaView-based visualization. Through a combination of theoretical lectures and hands-on exercises, participants will learn how to instrument a simulation code with PDI, configure it declaratively via YAML, and drive complex I/O and visualization workflows without modifying the simulation itself.
Attendees will leave with a practical understanding of how to adopt PDI in their own projects to create modular data workflows suited for HPC.
Website: https://pdi.dev/hpcasia26
Mon, January 26, 2026 9:30 - 16:30 Room 804
Contributors: Christian Trott and Damien Lebrun-Grandié
Abstract: This tutorial provides a introduction to Kokkos, a C++ programming model designed for application performance portability across diverse computing architectures. As modern high-performance computing (HPC) increasingly relies on heterogeneous systems featuring GPUs, multicore CPUs, and other accelerators, developers face the challenge of writing code that efficiently utilizes these varied hardware resources without developing and maintaining multiple variants of the software. Kokkos addresses this by offering a single-source approach, allowing users to write code once and compile it for optimal execution on a wide range of platforms. Kokkos is an Open Source project under the Linux Foundation’s “High Performance Software Foundation" (https://hpsf.io).
We'll start by exploring the fundamental concepts of Kokkos, including memory spaces and execution spaces, which are crucial for managing data placement and task execution on different devices. You'll learn about Kokkos::parallel_for for launching parallel computations and Kokkos::View for managing data arrays efficiently on various memory architectures. Through hands-on examples, we'll demonstrate how to port simple computational kernels to Kokkos, highlighting the benefits of its abstraction layers. By the end of this tutorial, beginners will have a solid foundation for developing performance-portable applications with Kokkos, enabling them to leverage the full power of modern HPC systems. No prior experience with parallel programming models like CUDA or OpenMP is required, though basic C++ knowledge is assumed.
Mon, January 26, 2026 9:30 - 16:30 Room 1009
Contributors: Anshu Dubey, David Bernholdt, and Akash Dhruv
Abstract: Producing scientific software is a challenge. The high-performance modeling and simulation community, in particular, faces the confluence of disruptive changes in computing architectures and new opportunities (and demands) for greatly improved simulation capabilities, especially through coupling physics and scales. Simultaneously, computational science and engineering (CSE), as well as other areas of science, are experiencing an increasing focus on scientific reproducibility and software quality. Large language models (LLMs), can significantly increase developer productivity through judicious off-loading of tasks. However, models can hallucinate, therefore it is important to have a good methodology to get the most benefit out of this approach.
We propose a tutorial in which attendees will learn about practices, processes, and tools to improve the productivity of those who develop CSE software, increase the sustainability of software artifacts, and enhance trustworthiness in their use. We will focus on aspects of scientific software development that are not adequately addressed by resources developed for industrial software engineering. We will additionally impart state-of-the-art approaches for using LLMs to enhance developer productivity in the context of scientific software development and maintenance. Topics include the design, test-driven development, refactoring, code translation and testing of complex scientific software systems; and conducting computational experiments with reproducibility built in.
The inclusion of LLM assistance on coding related tasks is particularly important to include in any software productivity concern given that it has the potential to change the way development is done. It is particularly challenging to get this assistance in developing research software because of limited training data. We have developed methodologies and tools for software development and translation that use LLMs. The use of these tools and methodologies for hands-on activities will be a part of this tutorial.
Website: https://bssw-tutorial.github.io/2026-01-26-hpcasia/
Mon, January 26, 2026 9:30 - 16:30 Room 801
Contributors: Cole Brower, Samuel Rodriguez, Hiroyuki Ootomo, Yevhenii Havrylko, Paweł Grabowski, Harun Bayraktar
Abstract: While libraries exist for most commonly used mathematical operations, developers often need to write custom kernels for functionality not covered by high-level APIs. A great example is "fusing" multiple operations into a single kernel, a well-established optimization strategy that reduces kernel launch overhead and can increase arithmetic intensity and minimize global memory traffic. These benefits are particularly impactful in performance-critical applications, such as attention mechanisms in large language models. Math Device Extension (MathDx) libraries were developed to enable the rapid development of such high-performance GPU kernels.
In this tutorial, we introduce the Dx ecosystem to the GPU kernel developer community, highlighting its use in both C++ and Python and how it makes it easy to write fast, portable GPU code. Python support is enabled via nvmath-python, which brings the power of Dx libraries to data scientists and research developers without sacrificing performance.
To ground these concepts in a meaningful application, we use floating-point emulation via the Ozaki-I scheme as a hands-on case study. Attendees will learn how to implement high-precision FP64 matrix multiplication on low-precision integer Tensor Cores using the cuBLASDx library and achieve near-cuBLAS performance. This will be accomplished through dedicated access to a GPU that has a very high INT8 to FP64 tensor core throughput ratio (e.g., Ada or Blackwell). Attendees must bring their own laptop and will have the opportunity to choose to do this either in C++ or in Python. This complex algorithm serves as a compelling example of how Dx libraries enable the rapid development of high-performance GPU kernels across both domains. If time permits, there will be a second exercise utilizing cuFFTDx.
Whether you’re an HPC practitioner looking to push the boundaries of performance or a developer seeking easier, more expressive GPU programming workflows, this tutorial will increase your productivity in writing high-performance GPU code.
Mon, January 26, 2026 9:30 - 16:30 Room 805
Contributors: Todd Gamblin, Gregory Becker, Alec Scott, Phil Sakievich, and Kathleen Shea
Abstract: Modern scientific software stacks rely on thousands of packages, from low-level libraries in C, C++, and Fortran to higher-level tools in Python and R. Scientists must deploy these stacks across diverse environments, from personal laptops to supercomputers, while tailoring workflows to specific tasks. Development workflows often require frequent rebuilds, debugging, and small-scale testing for rapid iteration. In contrast, preparing applications for large-scale HPC production involves performance-critical libraries (e.g., MPI, BLAS, LAPACK) and machine-specific optimizations to maximize efficiency.
Managing these varied requirements is challenging. Configuring software, resolving dependencies, and ensuring compatibility can hinder both development and deployment. Spack is an open-source package manager that simplifies building, installing, and customizing HPC software stacks. It offers a flexible dependency model, Python-based syntax for package recipes, and a repository of over 8,500 packages maintained by over 1,500 contributors. Spack is widely adopted by researchers, developers, cloud platforms, and HPC centers worldwide.
This tutorial introduces Spack's core capabilities, including installing, managing, and authoring packages, configuring environments, and deploying optimized software on HPC systems. The tutorial is divided into two halves: the first with introductory topics and the second with advanced workflows for developers, package maintainers, and facility staff. The format is interactive; presenters will work through live demos, which attendees can also work through in live cloud instances. Attendees will gain foundational skills for automating routine tasks and acquire advanced knowledge to address complex use cases with Spack.
Half Day: Morning
Mon, January 26, 2026 9:30 - 12:30 Room 1002
Contributors: Miwako Tsuji, Filippo Spiga
Abstract: This workshop aims to provide the opportunity to share the practice and experience of high-performance computing systems using the Arm architecture and their performance and applications.
The last few years have seen an explosion of 64-bit Arm-based processors targeted toward server and infrastructure workloads, often specializing in a specific domain such as HPC, cloud, and machine learning. A wide variety of Arm based processors such as Fujitsu A64FX, AWS Graviton, Microsoft Cobalt, Google Axion, Huawei Kunpeng and NVIDIA Grace, are available. More will come online in 2027.
Sharing the practice and experiences using these Arm-based processors will contribute to advancing high-performance computing technology for newly designed systems using these new emerging Arm-based processors.
In this workshop, we invite papers on the practice and experience of the Arm-based high-performance computing systems, if available, optimization and performance analysis of high-performance workloads on Arm-based processors. We welcome performance optimization studies either through access to real hardware or via simulation/emulation frameworks.
The topics include, but are not limited to:
- HPC Applications porting
- Performance Analysis, Performance Modeling & Measurement
- SVE Vectorization analysis and optimizations
- Programming Models & Systems Software
- Arm CPUs paired with Networking oir accelerators such as GPUs
- Applications of Arm technology to Artificial Intelligence and Machine Learning
- Emerging Arm-based CPU Architectures and Technologies
Website: https://iwahpce.github.io/
Call for Papers: Please see the website for details
Program:
- 09:30-09:55
- Score-P with Arm(s) around the world ...
- Christian Feld, Gregor Corbin and Brian J.N. Wylie (JSC)
- 09:55-10:20
- System Software Utilization on an ARM-Based Supercomputer: Insights from a Production-Scale System
- Yosuke Asai, Kento Sato, Keiji Yamamoto, Hitoshi Murai and Kohei Yoshida (RIKEN, The University of Electro-Communications)
- 10:20-10:45
- Cross-architecture power efficiency analysis through micro-benchmarking
- Fabio Banchelli, Filippo Mantovani and Filippo Spiga (BSC, NVIDIA)
- 10:45-11:15
- Break
- 11:15-11:40
- Solving large-scale eigen problem in quantum few-body system on massive parallel computer
- Daisuke Yoshida, Emiko Hiyama, Toshiyuki Imamura, Issaku Kanamori and Hideo Matsufuru (Tohoku University, RIKEN, KEK, SOKENDAI)
- 11:40-12:05
- Mixed precision solvers with half-precision floating point numbers for Lattice QCD on A64FX processor
- Issaku Kanamori, Hideo Matsufuru, Tatsumi Aoyama, Kazuyuki Kanaya, Yusuke Namekawa and Hidekatsu Nemura (RIKEN, KEK, SOKENDAI, The University of Tokyo, University of Tsukuba, Fukuyama University, Osaka University)
- 12:05-12:30
- Prototyping an Autotuning Framework for Program Optimization Using Exo Language
- Rin Iwai, Jens Domke, Emil Vatai and Yukinori Sato (Toyohashi University of Technology, RIKEN)
Mon, January 26, 2026 9:30 - 12:30 Room 1003 Room 702
Contributors: Neda Ebrahimi Pour, Sabine Roller, Ryoji Takaki
Abstract: The objective of this workshop is to provide a forum for the presentation and discussion of advanced numerical simulation techniques for complex multi-scale, multi-physics, coupled problems and AI enhanced simulations on high performance computing (HPC) systems.
Applications with different characteristics in parts of the computational domain can lead to unexpected performance issues. The optimum setting for one part might be contradictory to the optimum for another; the overall optimum might be non-optimal, but still a satisfactory compromise for researchers.
A variety of methodologies have been employed during the development of individual solutions, contingent upon the specific application and the underlying hardware configuration. In terms of the application, for example, machine learning algorithms have been introduced with a view to prediction purposes of simulation results. With regard to the hardware, the introduction of both homogeneous and heterogeneous cluster settings has been considered. All combinations have advantages and disadvantages, leading to the following question: how to find the optimal configuration and setting of all parameters, with respect to quality of solution vs. computational efficiency?
Call for Papers: Please see the website for details
Program:
- 9:30-9:35
- Welcoming
- Prof. Sabine Roller (DLR) & Prof. Ryoji Takaki (JAXA)
- 09:35-10:20
- Keynote: High-fidelity flow simulations using HPC solver FFVHC-ACE and parallelized Hankel dynamic mode decomposition for large-scale data
- Prof. Hiroyuki Asada (Tohoku University)
- 10:20-10:45
- Hybrid Inference Optimization for AI-Enhanced Turbulent Boundary Layer Simulation on Heterogeneous Systems
- Fabian Orland (RWTH Aachen University)
- 10:45-11:05
- Break
- 11:05-11:25
- CityScaleCast: Spatiotemporal GNN for City-Scale Weather Prediction with GraphCast-Guided Parallel Modeling and Multi-Step Forecasting in Sendai
- Xuanwen Pan (Tohoku University)
- 11:25-11:45
- Explainable AI-Guided Genetic Algorithms for Efficient Software Automatic Tuning
- Toshinobu Katayama (Tohoku University)
- 11:45-12:05
- MemMan: A Fortran and C++ Interoperable Memory Manager on Modern High-Performance Computing Platforms
- Claudius Holeksa (NORCE Research AS)
- 12:05-12:25
- Integrating Quantum and HPC: A Prototype Hybrid Implementation and Benchmark of Quantum-Selected Configuration Interaction
- Ikko Hamamura (NVIDIA Corporation)
- 12:25-12:30
- Closing Remarks
- Prof. Sabine Roller (DLR) & Prof. Ryoji Takaki (JAXA)
Mon, January 26, 2026 9:30 - 12:30 Room 702 Room 701
Contributors: Kai Watanabe, Shoichiro Tsutsui, Koji Kusunoki, Rei Nakatani
Abstract: This workshop will discuss applications of quantum computers to the field of CAE, an area expected to see broad use across industry and academia. In recent years, this field has come to be known as “QCAE,” and intensive research and development is being carried out by companies, universities, and research institutes. By leveraging quantum computing, QCAE is expected to enable high-accuracy numerical solutions for fluid simulations, large-scale structural analysis, and complex differential equations.
Aimed at participants of HPC/SCA 2026 who specialize in HPC, this workshop will guide you from the current status and basic principles of quantum computing through to cutting-edge QCAE initiatives, presented by leading experts. We expect that a basic understanding of numerical simulation—such as CAE computations using HPC and differential equations—will be sufficient to fully appreciate the content.
In addition to talks from top players in industry and academia, we are also planning informal discussions during the coffee break to enable closer and more open exchange of ideas.
Website: https://iqcae2026.github.io/homepage/en/page.html
Program:
- 09:40-10:05
- CAE in Quantum Computing: Business overview
- Tadashi Kadowaki (National Institute of Advanced Industrial Science and Technology (AIST) / DENSO CORPORATION)
- 10:05-10:30
- CAE in Quantum Computing: Technical overview
- Prof. Kosuke Mitarai (School of Engineering Science, Graduate School of Engineering Science / The University of Osaka)
- 10:30-11:00
- Break
- 11:00-11:20
- Latest Research presentation
- Prof. Shuta Kikuchi (Graduate School of Science and Technology, Keio University)
- 11:20-11:40
- Latest Research presentation
- Prof. Koichi Miyamoto (Center for Quantum Information and Quantum Biology, The University of Osaka)
- 11:40-12:00
- Latest Research presentation
- Kentaro Tanabe (Murata Manufacturing Co., Ltd., Corporate Technology & Business Development Unit, Senior Manager)
- 12:00-12:20
- Latest Research presentation
- Yuki Sato (Toyota Central R&D Labs., Inc.)
- 12:20-12:30
- Concluding Remarks
- Organizer (QunaSys, inc.)
Mon, January 26, 2026 9:30 - 12:30 Room 1101
Contributors: Antigoni Georgiadou, Tiernan Casey, Tushar Athawale
Abstract: The EPSOUQ-HPC workshop aims to close what we see as a key gap in the HPC/supercomputing technical content, i.e. a forum for deep discussion of topics at the interface of uncertainty quantification of predictive simulation and HPC. Our workshop welcomes technical contributions in all areas at the nexus of uncertainty quantification, optimization, modeling & simulation, and high-performance computing, while also targeting specific themes where these concepts are critical to technical success. In particular we are targeting digital twins, smart computing and weather simulation, and their interaction with generative AI models including language and image generation as themes where these nexus topics are of critical importance for developing, analyzing, and interpreting predictions. This year we are also expanding the UQ pillar to include research in uncertainty visualization, which is an important tool in enabling human interpretation of the outputs of probabilistic simulations.
Website: https://events.ornl.gov/epsouqhpc2025/
Program:
- 09:30-09:35
- Welcome & Introduction
- Dr. Antigoni Georgiadou (Oak Ridge National Laboratory (ORNL))
- 09:35-10:15
- Keynote presentation: “Actionable Predictions from HPC: Physics-Based +/- Artificial Intelligence”
- Dr. Peter Coveney (Univeristy College London (UCL))
- 10:15-10:45
- Speaker presentation: “Uncertainty Quantification of Frame Selection Methods for Adaptive Sampling in Molecular Dynamics”
- Dr. Vinod Jani (Center for Development of Advanced Computing, India (CDAC))
- 10:45-11:15
- Break
- 11:15-11:45
- Speaker presentation: “Compute Less, Learn More: HPC and UQ for Energy-Conscious Training”
- Dr. Sudip Seal (Oak Ridge National Laboratory (ORNL))
- 11:45-12:20
- Speaker presentation: “From Infrastructure to Reliability: QC-HPC Integration and Uncertainty-Driven Error Mitigation”
- Mr. Amir Shehata & Dr. Antigoni Georgiadou (Oak Ridge National Laboratory (ORNL))
- 12:20-12:30
- Closing remarks
Mon, January 26, 2026 9:30 - 12:30 Room 806
Contributors: Sadaf R. Alam, Maxime Martinasso, Alex Lovell-Troy, François Tessier, David Hancock, Winona Snapp-Childs
Abstract: Exascale computing initiatives are expected to enable breakthroughs for multiple scientific disciplines. Increasingly these systems may utilize cloud technologies, enabling complex and distributed workflows that can improve not only scientific productivity, but accessibility of resources to a wide range of communities. Such an integrated and seamlessly orchestrated system for supercomputing and cloud technologies is indispensable for experimental facilities that have been experiencing unprecedented data growth rates. While a subset of high performance computing (HPC) services have been available within a public cloud environments, petascale and beyond data and computing capabilities are largely provisioned within HPC data centres using traditional, bare-metal provisioning services to ensure performance, scaling and cost efficiencies. At the same time, on-demand and interactive provisioning of services that are commonplace in cloud environments, remain elusive for leading supercomputing ecosystems. This workshop aims at bringing together a group of experts and practitioners from academia, national laboratories, and industry to discuss technologies, use cases and best practices in order to set a vision and direction for leveraging high performance, extreme-scale computing and on-demand cloud ecosystems. Topics of interest include tools and technologies enabling scientists for adopting scientific applications to cloud interfaces, interoperability of HPC and cloud resource management and scheduling systems, cloud and HPC storage convergence to allow a high degree of flexibility for users and community platform developers, continuous integration/deployment approaches, reproducibility of scientific workflows in distributed environment, and best practices for enabling X-as-a-Service model at scale while maintaining a range of security constraints.
Website: https://sites.google.com/view/supercompcloud
Program:
- 09:30-9:55
- Overview of the OpenCHAMI project and Architecture
- Alex Lovell-Troy (Los Alamos National Lab)
- 09:55-10:20
- Bootstrapping and Cluster DevOps with OpenCHAMI
- Nick Jones and David Allen (Los Alamos National Lab)
- 10:20-10:45
- Resourceful and Sovereign HPC: Bristol Digital Labs and the StackHPC Slurm Appliance
- Stig Telfer (StackHPC)
- 10:45-11:15
- Break
- 11:15-11:40
- Deploying HPC and AI platforms on premise and on the Cloud
- Miguel Gila (Swiss National Supercomputing Center)
- 11:40-12:05
- RiVault: Towards self-hosted Agentic AI for Science and More
- Jens Domke (RIKEN)
- 12:05-12:30
- Automating National Federated AI Resource Access Management with AIRRPortal
- Christopher Woods (Bristol Centre for Supercomputing)
Mon, January 26, 2026 9:30 - 12:30 Room 1010
Contributors: JESUS CARRETERO, MARTIN SCHULZ, ESTELA SUAREZ
Abstract: The HPCMALL 2026 workshop will bring together researchers from diverse areas of HPC that are impacted by or actively pursuing malleability concepts, including application developers, system architects, programming model researchers, and system software researchers. In addition to high-quality, refereed publications and talks, the workshop will provide a lively discussion forum for researchers working in HPC and pursuing the concepts of and around malleability, to reflect on the advances achieved in the field since the previous editions of this workshop.
Website: https://coco-arcos.github.io/HPCMALL2026/
Call for Papers: Please see the website for details
Program:
- 09:30-09:40
- Workshop Opening.
- Martin Schultz (Technical University of Munich)
- 09:40-10:20
- Invited Keynote. "Malleable Architecture Design for the Computing Continuum: Addressing Energy, Workload, and Scale Diversity".
- Carlos J. Barrios (INSA-CITI Laboratory Lyon)
- 10:20-10:45
- On modeling knowledge graphs for representing and explaining wide-area distributed storage system.
- Dante D. Sánchez-Gallegos (University Carlos III of Madrid)
- 10:45-11:15
- Break
- 11:15-11:40
- Improving HPC Efficiency by Implementing Malleability Customisable Techniques in Radiation Transport Simulations.
- Rafael Mayo-Garcia (CIEMAT)
- 11:40-12:05
- Toward HPC Spot Jobs: On the Feasibility of Malleable Jobs on Idle Resources.
- Hervé Yviquel (Universidade Estadual de Campinas)
- 12:05-12:30
- Efficient Data Elasticity for HPC: A Malleable Ad-hoc In-memory File System for Ephemeral Data.
- Javier García-Blas (University Carlos III of Madrid)
- 12:30
- Workshop Closing.
- Martin Schultz Technical University of Munich
Mon, January 26, 2026 9:30 - 12:30 12F Conference Hall
Contributors: Makoto Taiji, Geetika Gupta
Abstract: This workshop aims to catalyze progress at the intersection of artificial intelligence and the natural sciences by highlighting the methodological challenges and opportunities that arise when applying AI techniques to domain-specific problems in life, material, physical sciences, and related fields. Despite recent successes, the integration of AI into scientific workflows remains non-trivial due to domain constraints such as limited labeled data, complex simulation-based environments, and the need for interpretability and physical consistency. The workshop provides showcase of recent successful developments of AI models for science and discussions on future directions.
Website: https://wahibium.github.io/advancing-science-through-ai/
Mon, January 26, 2026 9:30 - 12:30 Room 1201
Contributors: Nick Brown, Enrique S. Quintana-Ortí, Sandra Catalán
Abstract: The goal of this workshop is to continue building the community of RISC-V in HPC, sharing the benefits of this technology with domain scientists, tool developers, and supercomputer operators. RISC-V is an open standard Instruction Set Architecture (ISA) which enables the royalty free development of CPUs and a common software ecosystem to be shared across them. Following this community driven ISA standard, a very diverse set of CPUs have been, and continue to be, developed which are suited to a range of workloads. Whilst RISC-V has become very popular already in some fields, and in 2022 the ten billionth RISC-V core was shipped, to date it has yet to gain traction in HPC.
Website: https://riscv.epcc.ed.ac.uk/community/workshops/hpcasia26-workshop/
Program:
- 09:30-09:35
- Introduction
- Sandra Catalán (Universitat Jaume I)
- 09:35-10:25
- Invited talk
- Erich Focht (OpenChip)
- 10:25-10:45
- Porting and Evaluation of Lustre on a RISC-V Cluster for HPC Storage Infrastructure
- Surendra Billa (Centre for Development of Advanced Computing (C-DAC))
- 10:45-11:15
- Break
- 11:15-11:40
- Migration of Ginkgo's Jacobi-Preconditioned CG Solver to Vector RISC-V
- Enrique S. Quintana-Ortí (Universitat Politècnica de València)
- 11:40-12:05
- NIMA-STEP: A Hardware-Software Co-Design Approach for Accelerating Cellular Automata Computation
- Nima Sahraneshinsamani (Universitat Jaume I)
- 12:05-12:30
- An analysis of memory access patterns in RISC-V vector workloads on heterogeneous memory architectures
- Ryo Yokoyama (Graduate School of Information Sciences, Tohoku University)
Mon, January 26, 2026 09:30 - 12:30 Room 1008
Contributors: Sebastian Stern, Tyler Takeshita, and Benchen Huang
Abstract: Classical Quantum Monte Carlo (QMC) methods leverage high-performance computing (HPC) resources to simulate complex quantum many-body systems. Recently, these methods have been extended to quantum computers (QC) in hopes to achieve better accuracy. At the same time, architectures are being developed that enable such hybrid workflows by integrating quantum and HPC resources often hosted at different locations.
In this tutorial, we demonstrate a solution to an exemplary quantum many-body problem integrating distributed classical and quantum computing systems in the cloud. Specifically, we build an end-to-end workflow to execute the subroutines of a QMC algorithm on cloud-based batch and quantum computing resources and estimate the ground state energy of the example problem Hamiltonian.
The tutorial introduces QMC and QC basics to the participants and enables them to utilize cloud-native HPC and QC technologies for hybrid workloads. During the tutorial, participants will get free access to temporary AWS accounts and can follow along the guided steps in the QMC workflow. All attendees leave with code examples they can use as a foundation for their own projects.
Mon, January 26, 2026 9:30 - 12:30 Room 1001
Contributors: Dhabaleswar K (DK) Panda and Benjamin Michalowicz (The Ohio State University, USA)
Abstract: High-Performance Networking technologies are generating a lot of excitement towards building next generation High-End Computing (HEC) systems for HPC and AI with GPGPUs, accelerators, and Data Center Processing Units (DPUs), and a variety of application workloads. This tutorial will provide an overview of these emerging technologies, their architectural features, current market standing, and suitability for designing HEC systems. It will start with a brief overview of IB, HSE, RoCE, and Omni-Path interconnect. An in-depth overview of the architectural features of these interconnects will be presented. It will be followed with an overview of the emerging NVLink, NVLink2, NVSwitch, EFA, Slingshot, and Tofu-D architectures. We will then present advanced features of commodity high-performance networks that enable performance and scalability. We will then provide an overview of enhanced offload-capable network adapters like DPUs/IPUs (Smart NICs), their capabilities and features. Next, an overview of software stacks for high-performance networks like OpenFabrics Verbs, LibFabrics, and UCX, comparing the performance of these stacks will be given. Next, challenges in designing MPI libraries for these interconnects, solutions and sample performance numbers will be presented.
Website:https://nowlab.cse.ohio-state.edu/tutorials/SCA-HPCAsia-2026_hpn/
Mon, January 26, 2026 9:30 - 12:30 Room 1102
Contributors: Murali Emani, Leighton Wilson, and Petro Jr Milan
Abstract: Scientific applications are increasingly adopting Artificial Intelligence (AI) techniques to advance science. The scientific community is taking advantage of specialized hardware accelerators to push the limits of scientific discovery possible with traditional processors like CPUs and GPUs as demonstrated by the winners of ACM Gordon Bell prize recipients in recent years. The AI accelerator landscape can be daunting for the broader scientific community, particularly for those who are just beginning to engage with these systems. The wide diversity in hardware architectures and software stacks makes it challenging to understand the differences between these accelerators, their capabilities, programming approaches, and performance. In this tutorial, we will cover an overview of the AI accelerators available for allocation at Argonne Leadership Computing Facility (ALCF): SambaNova, Cerebras, Graphcore, and Groq, focusing on their architectural features and software stacks, including chip and system design, memory architecture, precision handling, programming models, and software development kits (SDKs). Through hands-on exercises, attendees will gain practical experience in refactoring code and running models on these systems, focusing on use cases of pre-training and fine-tuning open-source Large Language Models (LLMs) and deploying AI inference solutions relevant to scientific contexts. Additionally, the sessions will cover the low-level HPC software stack of these accelerators using simple HPC kernels. By the end of this tutorial, participants will have a solid understanding of the key capabilities of emerging AI accelerators and their performance implications for scientific applications, equipping them with the knowledge to leverage these technologies effectively in their research endeavors.
Mon, January 26, 2026 9:30 - 12:30 Room 1007
Contributors: Matthew Treinish, Julien Gacon, and Jun Doi
Abstract: Quantum computing is an emerging technology which has the potential to solve some
problems which are intractable for even the largest traditional supercomputer. By
leveraging quantum mechanical phenomena to perform computation, it can offer
exponential speedups for certain classes of problems. In recent years strategies have
emerged for combining HPC systems with quantum computers that leverage the unique
strengths of both computational models. The combination of high-performance computing
with quantum computing opens up the possibility for quantum computers to reach their
full potential.
This tutorial aims to provide an introduction to quantum computing for attendees. It will
provide an overview of quantum information theory, how to use quantum computers, and
the typical workflow when using a quantum computer. Building off that base knowledge,
the tutorial will explore different programming patterns which are compatible with typical
HPC workflows. It will specifically focus on using the Qiskit open source SDK and
demonstrate how you can use it to program quantum computers. This will include real-
world examples demonstrating hybrid HPC and quantum computing workflows.
Half Day: Afternoon
Mon, January 26, 2026 13:30 - 16:30 Room 1201 Room 701
Contributors: Tomohiro Ueno, Sheng Di
Abstract: In addition to traditional applications, the rise of AI and cloud computing has significantly increased the volume of data processing and communication required in high-performance computing (HPC).
Efficient data analytics and data movement across distributed and parallel environments (e.g., the Internet, inter-node networks, and system interconnects) have become critical factors in determining the performance and energy efficiency of supercomputers, data centers, and cloud platforms.
This workshop aims to address key research challenges related to big data from multiple perspectives, including data exploration, data compression, and big data systems.
To tackle these challenges, the workshop will aim to explore practical and effective approaches to data analytics and mining, big data visualization, data integration, scalable data compression, and storage/processing systems for big data.
These investigations will consider both the characteristics of large-scale data workloads and the constraints of modern hardware architectures.
In particular, the workshop will emphasize optimization strategies for big data processing, adaptive and general-purpose compression techniques, and high-performance systems designed for high-throughput, low-latency, and hardware-efficient data operations.
Website: https://sites.google.com/view/bdxcs2026/home
Call for Papers: https://drive.google.com/file/d/1DNpeDyVSZUZoMU7huAySe6yiUTBL3bEE/view?pli=1
Program:
- 13:30-13:35
- Opening
- Tomohiro Ueno (RIKEN R-CCS)
- 13:35-14:15
- Keynote 1
- Takaki Hatsui (RIKEN SPring-8 Center)
- 14:15-14:30
- Understanding LLM Checkpoint/Restore I/O Strategies and Patterns
- Mikaila Gossman, Avinash Maurya, Bogdan Nicolae, Jon Calhoun (Clemson University, Argonne National Laboratory)
- 14:30-14:45
- DeepEBC: Compressing the Pre-Trained LLMs with Error-Bounded Lossy Compression
- Jiaqi Xu, Zhaorui Zhang, Gaolin Wei, Sheng Di, Benben Liu, Xiaodong Yu, Xiaoyi Lu (Hong Kong Polytechnic University, Argonne National Laboratory, The University of Hong Kong, Stevens Institute of Technology, University of California, Merced)
- 14:45-15:15
- Break
- 15:15-15:55
- Keynote 2
- Xiaoyi Lu (University of Florida)
- 15:55-16:10
- Performance and Area Optimization of Lossless Hardware Compression of Floating-Point Data Streams
- Linyi Li, Jason Anderson, Tomohiro Ueno (University of Toronto, RIKEN)
- 16:10-16:25
- Parallelising Stream-Based Lossless Data Compression on GPUs and CPUs
- Yue Zhang, Yuki Hara, Oliver Sinnen, Shinichi Yamagiwa (University of Auckland, University of Tsukuba)
- 16:25-16:30
- Closing
- Tomohiro Ueno (RIKEN R-CCS)
This session has been cancelled due to unavoidable circumstances.
Mon, January 26, 2026 13:30 - 16:30 Room 1003
Contributors: Murali Emani, Gokcen Kestor, Dong Li
Abstract: Artificial Intelligence (AI) and Machine Learning (ML) are rapidly reshaping scientific discovery, enabling breakthroughs in climate prediction, materials design, astrophysics, drug development, and large-scale simulations. AI for Science (AI4S) seeks to accelerate innovation by integrating advanced learning methods into scientific workflows, yet key challenges persist. These include reliably and automatically applying AI/ML to complex scientific applications, incorporating domain knowledge such as physical constraints and symmetries, improving model robustness and interpretability for high-performance computing (HPC), refining foundation models for scientific use, and reducing the energy cost of large-scale training. As AI becomes increasingly central to scientific computing and influences HPC architectures and methodologies, coordinated efforts across disciplines are essential.
The AI4S workshop provides a forum for experts from academia, industry, and government to address these challenges and highlight emerging opportunities in AI-driven science. Through plenary talks, peer-reviewed papers, keynotes, and panel discussions, the workshop fosters collaboration between AI researchers, domain scientists, and HPC practitioners. Reflecting strong engagement in the supercomputing community—as demonstrated by record participation at prior events—the workshop aims to shape future AI research directions, advance integration of AI with HPC systems, and catalyze the next generation of AI-enabled scientific discoveries.
Program:
- 13:30-13:35
- Welcome
- Murali Emani (Argonne National Laboratory (ANL))
- 13:35-14:10
- Aeris: Argonne earth systems model for reliable and skillful predictions
- TBD (Argonne National Laboratory)
- 14:10-14:45
- Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
- Rio Yokota (Institute of Science, Tokyo)
- 14:45-15:15
- Break
- 15:15-15:50
- TBD
- Mohammed Wahib (RIKEN)
- 15:50-16.25
- TBD
- 16:25-16.30
- Conclusion
- Murali Emani (ANL)
Mon, January 26, 2026 13:30 - 16:30 Room 806
Contributors: Barton Fiske, Simon See, Akihiro Kishimoto
Abstract: Scientific visualization is undergoing a transformative era, driven by the explosion of data volumes, the advent of exascale computing, and the integration of artificial intelligence and machine learning. As simulations and applications of smart cities generate increasingly complex and massive datasets, the ability to analyze, interpret, and communicate these data visually is more critical than ever. Emerging trends include the use of visualization to minimize I/O bottlenecks, the development of scalable rendering techniques for handling billion-element datasets, and the growing role of interactive and immersive visualization environments for collaborative scientific and smart city discovery. Looking ahead, scientific visualization and digital twins are poised to become even more central to research and urban workflows, enabling real-time insights, supporting decision-making in smart city planning. The future of scientific visualization and digital twins lie in its ability to adapt to new computational paradigms and to empower researchers, city planners, and decision-makers with intuitive, powerful tools for exploring and understanding the unseen in smart cities.
This workshop aims to foster collaboration among visualization and digital twins experts, domain scientists, and technology developers to advance the state-of-the-art in scientific visualization and address the challenges posed by increasingly large and complex datasets in smart city applications. By sharing best practices, innovative tools, and real-world experiences, the workshop seeks to catalyze new research directions and practical solutions that enhance the accessibility and impact of visualization across urban environments. The influence of this workshop is to empower scientists and smart city stakeholders to communicate their findings more effectively and enabling real-time visualization for urban development. Ultimately, the workshop will help bridge the gap between advanced scientific computing, visualization, and smart city needs, ensuring that visualization remains a powerful force for discovery, understanding, and urban transformation.
Website: https://sites.google.com/view/svsc-workshop-scahpcasia-26
Program:
- 13:30-13:35
- Introduction and Opening Remarks
- 13:35-13:55
- Keynote – NVIDIA Blueprint for Smart City AI
- Barton Fiske (NVIDIA)
- 13:55-14:20
- Invited Talk – From CFD to Smart Visualization: Digital Twin Solutions for Urban Air Ventilation Analysis
- Kenneth Sung (Metason)
- 14:20-14:45
- Invited Talk – Visualization for Optimization of Scientific Simulations
- Takayuki Itoh (Ochanomizu University)
- 14:45-15:15
- Break
- 15:15-15:35
- Invited Talk – Visualization of Large-Scale Urban Crowd Movement for Evacuation and Safety Planning
- Kensuke Yasufuku (The University of Osaka)
- 15:35-16:00
- Invited Talk – Large-Scale Scientific Visualization using Universal Scene Description
- liff Ho (NVIDIA)
- 16:00-16:30
- Panel discussion
- Barton Fiske (NVIDIA), Jeff Adie (NVIDIA), Kenneth Sung (Metason), Takayuki Itoh (Ochanomizu University), Kensuke Yasufuku (The University of Osaka)
Mon, January 26, 2026 13:30 - 16:30 Room 1102
Contributors: Simon Garcia de Gonzalo, Mohammad Alaul Haque Monil, Norihisa Fujita
Abstract: While computing technologies have remained relatively stable for nearly two decades, new architectural features, such as specialized hardware, heterogeneous cores, deep memory hierarchies, and near-memory processing, have emerged as possible solutions to address the concerns of energy efficiency, manufacturability, and cost. However, we expect this ‘golden age’ of architectural change to lead to extreme heterogeneity and will have a major impact on software systems and applications. In this upcoming exascale and extreme heterogeneity era, it will be critical to explore new software approaches that will enable us to effectively exploit this diverse hardware to advance science, the next-generation systems with heterogeneous elements will need to accommodate complex workflows. This is mainly due to the many forms of heterogeneous accelerators (no longer just GPU accelerators) in this heterogeneous era, and the need to map different parts of an application onto elements most appropriate for that application component. In addition, this year we acknowledge the increasing need for Co-Design. This topic will explore the methodologies, challenges, and opportunities in the co-design of hardware, software, and applications to achieve optimal performance, power efficiency, and productivity in the era of extreme heterogeneity.
Website: https://ornl.github.io/events/exhet2026/
Call for Papers: Please see the website for details
Program:
- 13:30-13:40
- Opening Remarks
- Mohammad Alaul Haque Monil (Oak Ridge National Laboratory, USA)
- 13:40-13:55
- Paper Talk 1: Orchid: Towards Heterogeneous Batched Eigenvalue Solvers
- Matthew Chung (University of California, Riverside, USA)
- 13:55-14:30
- Keynote Talk: Extreme Heterogeneity on HPC/AI - What is the next stage?
- Taisuke Boku (University of Tsukuba, Japan)
- 14:30-14:45
- Paper Talk 2: Micro-Benchmarking Communications Libraries on the MI300A Compute Partitioning Modes
- Simon Garcia de Gonzalo (Sandia National Laboratories, USA)
- 14:45-15:15
- Break
- 15:15-15:30
- Paper Talk 3: DGEMM using FP64 Arithmetic Emulation and FP8 Tensor Cores with Ozaki Scheme
- Daichi Mukunoki (Nagoya University, Japan)
- 15:30-15:40
- Paper Talk 4: Q-IRIS: The Evolution of the IRIS Task-Based Runtime to Enable Classical-Quantum Workflows
- Elaine Wong (Oak Ridge National Laboratory, USA)
- 15:40-16:20
- Panel: The future of extreme heterogeneity solutions
- 16:20-16:30
- Paper Award and closing remark
Mon, January 26, 2026 13:30 - 16:30 Room 1101
Contributors: Toshihiro Hanawa
Abstract: IXPUG Workshop at HPC Asia 2026 is an open workshop on high-performance computing applications, systems, and architecture with Intel technologies. This is a half-day workshop with invited talks and contributed papers. The workshop aims to bring together software developers and technology experts to share challenges, experiences, and best-practice methods for the optimization of HPC, Machine Learning, and Data Analytics workloads. Any research aspect related to Intel HPC products is welcome to be presented in this workshop.
Website: https://www.ixpug.org/events/ixpug-hpc-asia-2026
Call for Papers: Please see the website for details
Program:
- 13:30-13:45
- Opening Remarks & Introduction of IXPUG
- Amit Ruhela (TACC)
- 13:45-14:25
- Keynote “High-Performance Mixed-Precision Sparse Matrix Solvers for Next-Generation Computational Science and Engineering"
- Takeshi Iwashita (Kyoto University)
- 14:25-14:35
- Site update (1): TACC
- Amit Ruhela (TACC)
- 14:35-14:45
- Site update (2): KAUST
- Hatem Ltaief (KAUST)
- 14:45-15:15
- Break
- 15:15-15:45
- "Large-Scale Vlasov Simulations for Astrophysics using Non-volatile Memory as Large Memory"
- Norihisa Fujita (University of Tsukuba)
- 15:45-15:55
- Site update (3): Osaka University
- Susumu Date (Osaka University)
- 15:55-16:05
- Site update (4): JCAHPC
- Toshihiro Hanawa (JCAHPC/The University of Tokyo)
- 16:05-16:30
- Invited talk: From k-mers to Kernels: High-Performance Computing for Wheat Genomes
- Hatem Ltaief (KAUST)
Mon, January 26, 2026 13:30 - 16:30 Room 702
Contributors: Jong Choi, Masaaki Kondo, Shruti Kulkarni, Seung-Hwan Lim, Tong Shu, Elaine Wong
Abstract: With the recent advancements in artificial intelligence, deep learning systems and applications have become a driving force in multiple transdisciplinary domains. This evolution has been supported by the rapid improvements of advanced processor, accelerator, memory, storage, interconnect and system architectures, including architectures based on future and emerging hardware (e.g., quantum, superconducting, photonic, neuromorphic). However, existing research is focused on hardware accelerators, deep learning systems and applications separately, but the co-design among them is largely underexplored. To develop high-performance deep learning systems on advanced accelerators, our workshop will focus on the following three important topics:
- adaptive deep learning model exploration and training for target inference devices based on customized user demands,
- joint optimization of deep learning model design with future accelerator architecture/compiler design, and
- how to leverage state-of-the-art computational functionalities from advanced accelerators for application optimization.
Website: https://shda-workshop.github.io/
Call for Papers: https://shda-workshop.github.io/html/call4papers.html
Program:
- 13:30-13:35
- Welcome to SCA/HPCAsia Workshp SHDA 2026
- Elaine Wong (Oak Ridge National Laboratory)
- 13:35-14:20
- Invited Talk: The power of Analogous computing
- John Shalf (Lawrence Berkeley National Lab)
- 14:20-14:45
- Contributed Talk: A Unidirectional Two-Compartment Neuron Circuit with On-chip STDP learning
- Shunta Furuichi (The University of Tokyo)
- 14:45-15:15
- Break
- 15:15-15:50
- Automated Approaches for Quantum Software-Hardware Co Design
- Lukas Burgholzer (Technical University of Munich, Munich Quantum Software Company)
- 15:50-16:25
- CGRA architectures for HPC and AI
- Boma A. Adhi (RIKEN)
- 16:25-16:30
- Concluding remark
- Seung-Hwan Lim (Oak Ridge National Laboratory)
Mon, January 26, 2026 13:30 - 16:30 Room 1008
Contributors: Chen Wang, Michael Brim, Jae-Seung Yeom, Michela Taufer, Ian Lumsden, Cameron Stanavige, Hariharan Devarajan, Kathryn Mohror
Abstract: As HPC applications grow in complexity and scale, I/O (Input/Output) performance remains a persistent bottleneck. Many modern workloads, including coupled simulations, AI integration, and in-situ analytics generate and consume large volumes of data that stress shared parallel file systems. This tutorial introduces practical techniques and tools to accelerate application I/O using fast, node-local storage, with a focus on two open-source solutions: UnifyFS and DYAD.
UnifyFS is a user-level file system that provides a shared namespace backed by node-local storage, enabling scalable, high-throughput I/O for write-heavy workloads. DYAD complements this by intelligently managing the data flow of dependent workflow components (e.g., simulation and analysis) to improve data locality for read-heavy workloads. Together, these systems offer a powerful approach to tackling I/O challenges without requiring major changes to application code.
This hands-on tutorial will guide participants through:
- The challenges of I/O performance at scale in HPC environments
- The design and capabilities of UnifyFS and DYAD
- How to deploy and configure these tools on HPC systems
- Integration with HPC applications (e.g., scientific simulations and AI training) and I/O libraries (e.g., MPI-IO, HDF5)
- Use cases demonstrating I/O acceleration
This tutorial is designed for a broad HPC audience - including researchers, application developers, and system engineers - who are interested in improving the performance and efficiency of I/O-bound workloads. Prior experience with UnifyFS or DYAD is not required. Attendees will leave with a deeper understanding of how to integrate node-local storage strategies into their workflows and with practical skills to apply on existing HPC systems.
Mon, January 26, 2026 13:30 - 16:30 Room 1001
Contributors: Dhabaleswar K (DK) Panda and Nawras Alnaasan (The Ohio State University, USA)
Abstract: Recent advances in Deep Learning (DL) have led to many exciting challenges and opportunities. Modern DL frameworks such as PyTorch and TensorFlow enable high-performance training, inference, and deployment for various types of Deep Neural Networks (DNNs). This tutorial provides an overview of recent trends in DL and the role of cutting-edge hardware architectures and interconnects in moving the field forward. We will also present an overview of different DNN architectures, DL frameworks, and DL Training and Inference with special focus on parallelization strategies for large models such as GPT, LLaMA, DeepSeek, and ViT. We highlight new challenges and opportunities for communication runtimes to exploit high-performance CPU/GPU architectures to efficiently support large-scale distributed training. We also highlight some of our co-design efforts to utilize MPI for large-scale DNN training on cutting-edge CPU/GPU/DPU architectures available on modern HPC clusters. Throughout the tutorial, we include several hands-on exercises to enable attendees to gain first-hand experience of running distributed DL training on a modern GPU cluster.
Website: https://nowlab.cse.ohio-state.edu/tutorials/hidl_SCAsia26/
Mon, January 26, 2026 13:30 - 16:30 Room 1002
Contributors: Yuji Iguchi, Hitoshi Murai, Todd Churchward, Kei Sasaki, and Shun Utsui
Abstract: Researchers and HPC practitioners increasingly face the challenge of maintaining consistent software environments across diverse computing resources. As scientific workflows span multiple institutions and migrate between on-premises clusters and cloud platforms, environment inconsistency leads to wasted time, reproducibility challenges, and inefficient resource utilization. RIKEN Center for Computational Science (R-CCS) and Amazon Web Services (AWS) will demonstrate how they overcame these challenges with the "Virtual Fugaku" strategy. This tutorial demonstrates how cloud infrastructure combined with containerized software environments enables researchers to develop once and run anywhere, eliminating boundaries between computing resources. Participants will first learn to build cloud-based HPC environments, then explore how portable software stacks like those in the Virtual Fugaku project maintain consistency across diverse infrastructures.
Through lectures and hands-on labs, participants will gain understanding of both cloud HPC deployment and workload portability while maintaining performance. The tutorial explores practical approaches for building infrastructure and running consistent workloads across different environments.
Participants will apply learning through two hands-on labs: building a cloud-based HPC
cluster, then deploying portable, containerized environments. Attendees will gain
knowledge to effectively deploy and optimize portable HPC workloads across diverse
computing resources.
Mon, January 26, 2026 13:30 - 16:30 Room 1007
Contributors: Munetaka Ohtani, Shweta Salaria, and Yoonho Park
Abstract: Quantum computing has the potential to elevate heterogeneous high-performance computers to tackle problems that are intractable for purely classical supercomputers. Integrating quantum processing units (QPUs) into a heterogeneous compute infrastructure, referred to as the quantum-centric supercomputing (QCSC) model, involves CPUs, GPUs, and other specialized accelerators (AIUs, etc.). Achieving this requires collaboration across multiple industries to align efforts in integrating hardware and software.
IBM and our HPC/Quantum partners have developed software components to enable the handling of QPU workloads within the Slurm workload manager in HPC environments. This tutorial session will provide a comprehensive overview of the architecture, demonstrate how to create Slurm jobs for executing quantum workloads, and discuss the execution of Quantum-Classical hybrid workloads. Participants will gain hands-on experience though live demonstrations, exploring the integration of quantum workloads into existing HPC systems.
Efficient scheduling is only part of the solution. In the second half of the session, we will address the orchestration challenges unique to hybrid Quantum-Classical workloads—such as iterative execution, hyperparameter tuning, and backend instability. Participants will learn how to build scalable, fault-tolerant pipelines using Python-based workflow tools like Prefect. Key features such as checkpointing, automatic retries, and real-time observability will be demonstrated live, equipping attendees with the skills to manage complex quantum workloads and prepare for future challenges in scalability and reproducibility.
Tue, January 27, 2026 09:00 - 09:30 5F Main Hall
Tue, January 27, 2026 9:30 - 17:00
Wed, January 28, 2026 9:00 - 17:00
Thu, January 29, 2026 9:00 - 15:30
Venue: 3F Event Hall
Exhibitor List:
Nearly 100 exhibitors will showcase their latest technologies, products, and research results. Please see the exhibitor list and floor map below.
Exhibitor List and Floor Plan (PDF)
Exhibitors Forum:
During the exhibition hours, exhibitors will deliver 15-minute presentations. Please see the detailed program below.
Exhibitors Forum
Tue, January 27, 2026 09:30 - 10:15 5F Main Hall
Session Chair: Rio Yokota (Institute of Science Tokyo/RIKEN)

Speaker
- Torsten Hoefler
- Professor
ETH Zurich, Switzerland
Biography
Torsten Hoefler is a Professor of Computer Science at ETH Zurich, a member of Academia Europaea, and a Fellow of the ACM, IEEE, and ELLIS. He received the 2024 ACM Prize in Computing, one of the highest honors in the field. Following a Performance as a Science vision, he combines mathematical models of architectures and applications to design optimized computing systems. Before joining ETH Zurich, he led the performance modeling and simulation efforts for the first sustained Petascale supercomputer, Blue Waters, at the University of Illinois at Urbana-Champaign. He is also a key contributor to the Message Passing Interface (MPI) standard where he chaired the "Collective Operations and Topologies" working group. Torsten won best paper awards at his field's top conference ACM/IEEE Supercomputing in 2010, 2013, 2014, 2019, 2022, 2023, 2024, and at other international conferences. He has published numerous peer-reviewed scientific articles and authored chapters of the MPI-2.2 and MPI-3.0 standards. For his work, Torsten received the IEEE CS Sidney Fernbach Memorial Award in 2022, the ACM Gordon Bell Prize in 2019, Germany's Max Planck-Humboldt Medal, the ISC Jack Dongarra award, the IEEE TCSC Award of Excellence (MCR), ETH Zurich's Latsis Prize, the SIAM SIAG/Supercomputing Junior Scientist Prize, the IEEE TCSC Young Achievers in Scalable Computing Award, and the BenchCouncil Rising Star Award. Following his Ph.D., he received the 2014 Young Alumni Award and the 2022 Distinguished Alumni Award of his alma mater, Indiana University. Torsten was elected to the first steering committee of ACM's SIGHPC in 2013 and he was re-elected for every term since then. He was the first European to receive many of those honors; he also received both an ERC Starting and Consolidator grant. His research interests revolve around the central topic of performance-centric system design and include scalable networks, parallel programming techniques, and performance modeling for large-scale simulations and artificial intelligence systems. Additional information about Torsten can be found on his homepage at htor.inf.ethz.ch.
Abstract
The Ultra Ethernet Consortium set out to redefine Ethernet-based interconnects for AI and high-performance computing (HPC), culminating in the recent release of its first specification (version 1.0). This talk will analyze HPC and AI workloads with respect to their networking requirements. We will then highlight key innovations that distinguish Ultra Ethernet from existing solutions, ranging from lossy operation—both with and without trimming—to fully hardware-offloaded rendezvous protocols. We will explore the architectural advancements and technical highlights that enhance efficiency, scalability, and performance, positioning Ultra Ethernet as a transformative force in next-generation computing.
Tue, January 27, 2026 10:15 - 11:00 5F Main Hall
Session Chair: Kengo Nakajima (University of Tokyo/RIKEN)

Speaker
- Keisuke Fujii
- Distinguished Professor
The University of Osaka, Japan
Biography
Keisuke Fujii is a Distinguished Professor at the Graduate School of Engineering Science, Osaka University, where he also serves as Deputy Director of the Center for Quantum Information and Quantum Biology (QIQB). He concurrently leads a research team at the RIKEN Center for Quantum Computing and acts as Chief Technical Advisor at QunaSys Inc., a leading quantum computing software start-up in Japan. He received his Ph.D. in Engineering from Kyoto University in 2011, and has held academic positions at the University of Tokyo and Kyoto University before joining Osaka University in 2019.
Professor Fujii’s research spans a broad spectrum of quantum information science, with a primary focus on the theory of fault-tolerant quantum computation, quantum error correction, quantum algorithms. His achievements have been recognized with the NISTEP Award (2020), the JSPS Prize (2022), and the Osaka University Distinguished Professor title (2022).
Abstract
The past decade has witnessed remarkable progress in the development of quantum computers, culminating in the current era of noisy intermediate-scale quantum (NISQ) devices. While NISQ hardware has enabled first demonstrations of quantum advantage in carefully chosen tasks, its limited qubit number and error rates severely restrict practical applications. Bridging the gap toward fault-tolerant quantum computing (FTQC) requires both architectural innovation and resource-efficient error correction strategies. In this talk, I will provide an overview of the state of the art, highlighting how recent advances in algorithms, quantum error correction, and partially fault-tolerant architectures can pave the way for scalable computation. I will discuss how algorithm design and resource estimation are evolving hand in hand with hardware progress, shaping a roadmap from proof-of-principle demonstrations to early fault-tolerant applications. Special emphasis will be placed on the notion of “early FTQC,” which seeks to exploit partial fault tolerance to reduce overhead while delivering meaningful computational power. By connecting theoretical advances with experimental milestones, I aim to illustrate how high-performance quantum computing may emerge in the future and outline the key challenges and opportunities that lie ahead on the path from NISQ to FTQC.
Tue, January 27, 2026 11:30 - 12:30 Room 1003
Contributors: Addison Snell (Intersect360 Research)
Abstract: In this fast-paced panel format, Addison Snell invites four panelists – two from HPC and AI-using sites (ideally one lab, one industrial) and to from the vendor community (possibly SCA / HPC Asia sponsors) to play the role of the industry analyst by responding to forward-looking questions about the direction of the industry. The panel will address seven topics in 45 minutes. The audience will see the topic list and questions for the panelist on slides, with a timer, and the slides will auto-advance as the timer expires.
Panelists:
- Murali Emani, Argonne National Laboratory
- Sabine Roller, TU-Dresden
- Andrew Jones, Microsoft Azure
- Yoshihiro Kusano, Fujitsu
Tue, January 27, 2026 11:30 - 12:30 Room 702
Contributors: Eric Van Hensbergen (Arm)
Abstract: The exponential growth in compute demand from AI workloads has led to increasingly challenging infrastructure requirements. This panel brings together industry leaders to discuss how AI accelerators, compute racks, and AI clusters are evolving to address these requirements. In this panel session, panelists will highlight how future innovations in compute, accelerators, networking, optics, and cooling can enable greater compute capacity, efficiency, and performance at scale.
Speakers:
- Eric Van Hensbergen (Arm)
- Mohamed Wahib (RIKEN)
- Jay Boisseau (Google HPC)
- Jason Haga (AIST)
- Dan Ernst (Nvidia)
- Jennifer Glore (Rebellions)
Tue, January 27, 2026 11:30 - 17:00 Room 1001
Wed, January 28, 2026 11:00 - 17:00 Room 1001
Contributors: Taisuke Boku (University of Tsukuba), Andrew Rohl (National Computational Infrastructure (NCI), the Australian National University (ANU))
Abstract: As AI reshapes the global research and innovation landscape, national supercomputing centers across the Asia-Pacific and the world are evolving rapidly to meet new demands. Building on five years of dialogue through the SCAsia HPC Centre Leaders Forum and the growing collaboration within the Alliance of Supercomputing Centres (ASC), this session proposes the establishment of a dedicated HPC Centers Forum at SCAsia/HPCAsia 2026. Co-chaired by Taisuke Boku (Center for Computational Sciences, University of Tsukuba, Japan) and Andrew Rohl (National Computational Infrastructure, the Australian National University, Australia), the session will showcase how HPC centers across the region are pivoting in response to AI—reimagining infrastructure architectures, adapting research workflows, refining service delivery models, evolving resource allocation strategies, and engaging new user communities. The session will feature a curated selection of short presentations from regional HPC leaders, highlighting center-level strategies and national policy drivers. We will share the insights, cross-center learning, and discussion of future collaboration opportunities across APAC and the world. The HPC Centers Forum aims to become a recurring feature of SCAsia/HPCAsia, reinforcing regional leadership, enabling collective action, and fostering a coordinated response to the global HPC, AI and more convergence challenge.
Program:
Day 1, Jan 27 (Tue):
- 11:30-11:50
- Information Initiative Center
- Takeshi Fukaya (Hokkaido University)
- 11:50-12:10
- Cyberscience Center
- Hiroyuki Takizawa (Tohoku University)
- 12:10-12:30
- Center for Computational Sciences
- Taisuke Boku (University of Tsukuba)
- 12:30-13:30
- Lunch
- 13:30-14:00
- European High Performance Computing Joint Undertaking
- Anders Jensen (EuroHPC JU)
- 14:00-14:20
- Korea Institute of Science and Technology Information
- Chan-Yeol Park (KISTI)
- 14:20-14:40
- Argonne National Laboratory
- Brice Videau (ANL)
- 14:40-15:00
- National Supercomputing Centre Singapore
- Terence Hung (NCCS Singapore)
- 15:00-15:30
- Break
- 15:30-15:50
- National Institute of Informatics
- Kento Aida (NII)
- 15:50-16:10
- Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures
- Takumi Honda (University of Tokyo)
- 16:10-16:30
- D3 Center
- Susumu Date (University of Osaka)
- 16:30-17:00
- RIKEN Center for Computational Science
- Satoshi Matsuoka (R-CCS)
Day 2, Jan 28 (Wed):
- 11:00-11:30
- Lawrence Livermore and Oakridge National Laboratories
- Bronis R. de Supinski (LLNL)
- 11:30-11:50
- National Computational Infrastructure and Pawsey Supercomputing Research Centre
- Andrew Rohl (ANU)
- 11:50-12:10
- Jülich Supercomputing Centre
- Bernd Mohr (JSC)
- 12:10-12:30
- Swiss National Computing Centre
- Thomas Schulthess (CSCS)
- 12:30-13:30
- Lunch
- 13:30-13:50
- Information Technology Center
- Kengo Nakajima (University of Tokyo)
- 13:50-14:10
- Supercomputing Research Center/Center for Information Infrastructure
- Toshio Endo (Institute of Science Tokyo)
- 14:10-14:30
- Information Technology and Human Factors
- Ryousei Takano (National Institute of Advanced Industrial Science and Technology)
- 14:30-14:50
- Research Institute for Information Technology
- Kazuki Yoshizoe (Kyushu University)
- 15:00-15:30
- Break
- 15:30-15:50
- Texas Advanced Computing Center
- Dan Stanzione (University of Texas)
- 15:50-16:10
- IT Center for Science
- Kimmo Koski (CSC)
- 16:10-16:30
- National Center for High-performance Computing
- Weicheng Huang (NCHC)
- 16:30-16:50
- Bristol Centre for Supercomputing
- Sadaf Alam (BriCS)
Tue, January 27, 2026 11:30 - 17:00 Room 1102
Contributors: Dale Barker (Centre for Climate Research Singapore (CCRS)), Shigenori Otsuka (RIKEN R-CCS)
Abstract: Numerical Weather Prediction (NWP) and climate modelling have for decades relied on traditional ‘physical’ models, which provide numerical approximations to the Navier Stokes, thermodynamics, and wider Earth System processes discretized and parameterized for solution on some of the world’s largest supercomputers. The balance between model complexity, accuracy, uncertainty representation, time-to-solution etc. is an important consideration for weather/climate applications ranging from operationally ‘nowcasting’ local rainfall in the next 30 minutes, to simulating the global climate systems under various greenhouse gas emissions scenarios over coming decades.
Recent expansion of the use of data-driven (AI and machine learning) techniques to replace (or in the case of hybrid modelling – complement) physics-based approaches has instigated a revolution in NWP and climate modelling. ML-based approaches are now being considered across every stage of the weather/climate data processing chain, ranging from algorithm-specific (e.g. QC, data assimilation, process emulation, bias correction, post-processing, etc.) to full end-to-end (e.g. observation to forecast) approaches.
This session will draw together practitioners in computationally-intensive weather/climate science from world-leading research institutes, operational weather centres, national compute organisations, and the private sector. Speakers will outline their unique priorities and approaches to solving weather/climate challenges, and the specific role of large-scale compute and AI within these national and international endeavours.
Program:
- 11:30-12:00
- Stan Posey, HPC Program Manager, ESM and CFD Domains, NVIDIA
- 12:00-12:30
- Hisashi Yashiro, Senior Researcher, Earth Systems Division, National Institute for Environmental Studies (NIES)
- 12:30-13:30
- Lunch
- 13:30-14:00
- Mohamed Wahib, Team Principal, High Performance Artificial Intelligence Systems Research Team, RIKEN R-CCS
- 14:00-14:30
- Yuta Hirabayashi, Data Science Research Group, Japan Agency for Marine-Earth Science and Technology
- 14:30-15:00
- Shigenori Otsuka, Senior Research Scientist, Data Assimilation Research Team, RIKEN R-CCS
- 15:00-15:30
- Break
- 15:30-16:00
- Dale Barker, Director, Centre for Climate Research Singapore
- 16:00-16:30
- Kohei Kawano, Numerical Prediction Development Center, Japan Meteorological Agency
- 16:30-17:00
- Thomas Schulthess, Director of the Swiss National Supercomputing Centre (CSCS)
- 17:00-17:30
- Panel discussion
Tue, January 27, 2026 11:30 - 17:00 12F Conference Hall
Contributors: Arvind Ramanathan (Argonne National Laboratory), Newton Wahome (Coalition for Epidemic Preparedness innovations (CEPI))
Abstract: The COVID-19 pandemic revealed critical gaps in our ability to rapidly characterize emerging pathogens and design countermeasures. This session presents the Pandemic Preparedness Engine (PPX), an ambitious initiative by the Coalition for Epidemic Preparedness Innovations (CEPI) to establish a global network of "AI Factories" at leading supercomputing centers. These facilities will integrate high-performance computing, AI/ML, and automated experimental validation to compress vaccine development timelines from years to 100 days. Distinguished speakers from participating institutions—including Argonne National Laboratory (USA), Jülich Supercomputing Centre (Germany), Korea Institute of Science and Technology Information (KISTI), and other global partners—will discuss the technical architecture, AI workflows for viral variant prediction, protein structure determination, and immunogen design. The session will address challenges in data sovereignty, model sharing across borders, integration of heterogeneous HPC resources, and balancing open science with biosecurity concerns. By bringing together computational biologists, HPC center directors, public health officials, and AI researchers, this session aims to catalyze international collaboration and establish best practices for using supercomputing as critical infrastructure for global health security.
Website: https://cepi.net/
Program:
- 11:00-11:15
- Vision and Architecture of the Pandemic Preparedness Engine
- Drs. Newton Wahome (CEPI)/ Arvind Ramanathan (University of Chicago/ Argonne National Laboratory)
- 11:15-11:45
- Speaker 1: From Pathogen Detection to Vaccine Deployment
- Dr. Martin Steinegger, Seoul National University
- 11:45-12:05
- Speaker 2: Agentic systems for vaccine design
- Drs. Ian Foster/ Rick Stevens, University of Chicago/ Argonne National Laboratory
- 12:05-12:25
- Speaker 3: The Disease X Knowledge Base (DXKB)
- Drs. Jim Davis/ Arvind Ramanathan, Argonne National Laboratory/ University of Chicago
- 12:25-12-45
- Speaker 4: University of Melbourne
- 12:45-14:00
- Lunch Break
- 14:00-14:20
- Speaker 5: European Perspective on Cross-Border HPC Coordination
- Dr. Mathis Bode, Julich Supercomputing Center
- 14:20-14:40
- Speaker 6: Current Status of AI/HPC-based Research on Infectious Disease Response in Korea
- Dr. Insung Ahn, KISTI
- 14:40-15:00
- Speaker 7: AI-guided Design for RNA-based vaccine Platform
- Dr. Nick Jones, Auckland, New Zealand
- 15:00-15:30
- Break
- 15:30-16:00
- Speaker 8: Responsible Innovation and Global Equity
- Matt Doxey, Google
- 16:00-16:45
- Panel Discussion: Building a Sustainable Global Infrastructure (All speakers)
- 16:45-17:00
- Audience Q&A and Closing Remarks
Tue, January 27, 2026 11:30 - 17:00 Room 1202
Wed, January 28, 2026 11:00 - 17:00 Room 1202
Contributors: Rio Yokota, Charlie Catlett
Abstract: The TPC is a global initiative that brings together scientists from government laboratories, academia, research institutes, and industry to tackle the immense challenges of building large-scale AI systems for scientific discovery. By focusing on the development of massive generative AI models, the consortium aims to advance trustworthy and reliable AI tools that address complex scientific and engineering problems. Target community includes (a) those working on AI methods development, NLP/multimodal approaches and architectures, full stack implementations, scalable libraries and frameworks, AI workflows, data aggregation, cleaning and organization, training runtimes, model evaluation, downstream adaptation, alignment, etc.; (b) those that design and build hardware and software systems; and (c) those that will ultimately use the resulting AI systems to attack a range of problems in science, engineering, medicine, and other domains.
Website: https://tpc.dev/tpc-track-at-sca-hpca26/
Program:
Day 1, Jan 27 (Tue)
- 11:30-12:30
- Session 1.1: TPC International Collaborative Initiatives
- Workshop Welcome and Overview (Rio Yokota (IST), Charlie Catlett (Argonne))
- Open Frontier Model: Rio Yokota (IST)
- Evaluation: Franck Cappello (Argonne)
- Agentic AI and Scientific Discovery: Robert Underwood (Argonne)
- Driving Applications: Valerie Taylor (Argonne)
- 12:30-13:30
- Lunch Break
- 13:30-15:00
- Session 1.2: TPC Vision and Strategies (Moderator: Rio Yokota, Institute of Science Tokyo/RIKEN)
- The Transformational AI Models Consortium (ModCon): Neeraj Kumar (PNNL)
- EuroTPC: Fabrizio Gagliardi (BSC)
- Collaborations in AI4S – Now and Future: Satoshi Matsuoka (RIKEN)
- U.S. Department of Energy Genesis Mission: Rick Stevens (Argonne)
- 15:00-15:30
- Break
- 15:30-17:00
- Session 1.3: Selected TPC Technical Working Group Updates (Moderator: Charlie Catlett, ANL/UChicago)
- AI for Life Sciences and Healthcare: Makoto Taiji (RIKEN)
- Toward Next-Generation Ecosystems for Scientific Computing: Workshop Summary: Anshu Dubey (Argonne)
- AI for Drug Discovery: Arvind Ramanathan (Argonne)
- Panel
Day 2, Jan 28 (Wed)
- 11:00-12:30
- Session 2.1: AI for Science (Moderator: Neeraj Kumar, PNNL)
- Evaluation of Geospatial Foundation Models: Kyoung-Sook Kim (AIST)
- Vision Foundation Models for Weather and Climate Downscaling: Mohamed Wahib (RIKEN)
- LUMI AI Factory – for Science and Business: Pekka Manninen (CSC)
- When Language Models Learn from Themselves: Synthetic Data and Scientific Knowledge: Javier Aula-Blasco (BSC)
- 12:30-13:30
- Lunch Break
- 13:30-15:00
- Session 2.2: Agentic AI
- Agentic Large Language Model Copilots for Scientific Workflows: Anurag Acharya (PNNL)
- Agentic AI vs ML-based Autotuning: A Comparative Study for Loop Reordering Optimization: Khaled Ibrahim (LBNL)
- Breaking Barriers in Science: The AI and Hybrid Computing Evolution: Thierry Pellegrino (AWS)
- System Requirements for Scalable Agentic AI: Ian Foster (ANL)
- 15:00-15:30
- Break
- 15:30-17:00
- Session 2.3: Inference Services (Moderator: Anurag Acharya, PNNL)
- Secure AI Infrastructure for Scientific Computing and Applications: Jens Domke (RIKEN)
- VibeCodeHPC: Takahiro Katagiri (Nagoya University)
- The TPC Academic Scientific Inference Group: Perspectives from Around the World: Dan Stanzione (TACC)
- Daria Soboleva (Cerabras): Mixture of Experts at Scale on Cerebras Hardware
Tue, January 27, 2026 11:30 - 17:00 Room 1009
Contributors: Kengo Nakajima, France Boillod-Cerneux
Abstract: HANAMI is a collaborative initiative that fosters scientific partnerships between European and Japanese research institutions, with a focus on high-performance computing (HPC) and Artificial Intelligence (AI) at the exascale level and beyond. Bringing together leading research centers and supercomputing facilities, HANAMI targets key priority domains that are climate and weather modeling, biomedical research, and materials science. HANAMI promotes the mobility of researchers between the EU and Japan, while also developing a strategic roadmap to deepen and sustain transcontinental cooperation. This session will highlight HANAMI’s progress on joint scientific projects led by European and Japanese teams, and will offer insights into the future direction of the collaboration.
Website: https://hanami-project.com/
Program:
- 11:30-11:40
- Welcome
- France Boillod-Cerneuxm (CEA, France), Kengo Nakajima (UTokyo/RIKEN, Japan)
- 11:40-12:00
- EU-Japan Digital Partnership – Perspective from the Japan
- Kiyoshi Kurihara (MEXT, Japan)
- 12:00-12:20
- EU-Japan Digital Partnership – Perspective from the EU
- Peter Fatelnig (Delegation of the European Union to Japan, EU)
- 12:20-12:40
- What EuroHPC JU can offer for EU-Japan collaboration - practical guidelines
- Rafał Duczmal (EuroHPC JU Governing Board, EU)
- 12:40-13:30
- Lunch
- 13:30-13:50
- Elucidating Biomolecular Conformational Dynamics through Cryo-EM and High-Performance Computing
- Florence Tama (RIKEN/Nagoya University, Japan)
- 13:50-14:10
- Exascale electrostatics & machine learning to enable molecular dynamics of cell-size systems
- Erik Lindahl (KTH, Sweden)
- 14:10-14:30
- Leveraging Deep-learning and Large Language Model (LLM)-Inspired Architectures to Analyze Tabular Health Data
- Edouard Audit (CEA, France)
- 14:30-14:50
- HPC for Climate Modelling: Challenges and Opportunities at Exascale and Beyond
- Mario Acosta (BSC, Spain)
- 14:50-15:30
- Break
- 15:30-15:50
- Multiscale Cloud Microphysics Modeling from Aerosols to Convection with the Super-Droplet Method
- Shin-Ichiro Shima (University of Hyogo, Japan)
- 15:50-16:10
- EU-Japan Collaborations on Large-Scale Quantum Mechanical Modelling
- William Dawson (RIKEN, Japan)
- 16:10-16:30
- Advancing HPC-Driven Materials-Science Simulations through European–Japanese Collaboration in HANAMI
- Daniele Varsano (CNR, Italy)
- 16:30-16:40
- Closing
- France Boillod-Cerneux (CEA, France), Kengo Nakajima (UTokyo/RIKEN, Japan)
Tue, January 27, 2026 11:30 - 12:30 Room 1002
Chair: Jan Erik Reinhard Wichmann (RIKEN)
- 11:30 - 12:00
- "GCAMPS: A Scalable Classical Simulator for Qudit Systems"
- Ben Harper, Azar Nakhl, Thomas Quella, Martin Sevior, Muhammad Usman
- 12:00 - 12:30
- "EmuPlat: A Framework-Agnostic Platform for Quantum Hardware Emulation with Validated Transpiler-to-Pulse Pipeline"
- Jun Ye, Jun Yong Khoo
Tue, January 27, 2026 11:30 - 12:30 Room 1008
Chair: Francesco Antici (RIKEN)
- 11:30 - 12:00
- "ChatMPI: LLM-Driven MPI Code Generation for HPC Workloads"
- Pedro Valero-Lara, Aaron Young, Thomas Naughton III, Christian Engelmann, Al Geist, Jeffrey S. Vetter, Keita Teranishi, William F. Godoy
- 12:00 - 12:30
- "TRIOS: Reducing File-System Contention through Predictive Time-Resolved I/O Simulation in Job Scheduling"
- YuTsen Tseng, Masatoshi Kawai, Keichi Takahashi, Hiroyuki Takizawa
Tue, January 27, 2026 12:30 - 13:30 Room 1001
Title: Powering HPC and AI with High-Performance Data Infrastructure
- Session Overview
- This session explores the convergence of HPC and AI infrastructure, and why DDN has become the platform of choice for high-performance, scalable, and reliable data workflows. We will also introduce DDN Infinia, our next-generation data platform designed to accelerate AI workloads at scale.
- Speakers
-
- Shuichi Ihara, Koji Tanaka(DataDirect Networks)
- Chris J. Newburn(NVIDIA/Guest Speaker)
Tue, January 27, 2026 12:30 - 13:30 Room 1002
Title: Innovative AI HPC solutions that enable advanced, AI-intensive supercomputing
- Session Overview
- As AI rises in every field and HPC is compelled to integrate with AI, next-generation HPC solutions are entering a truly transformative era. Our company proposes this innovative AI HPC solution that enables advanced supercomputing with AI-intensive capabilities.
- Speakers
-
- Dmitry Livshits (Xinnor CEO)
- Tsuyoshi Okawa
- Kazuhiro Hirano
- Chiaki Nishikawa
Tue, January 27, 2026 12:30 - 13:30 Room 1003
Title: HPC and Cloud ~challenges and future vision ~
- Session Overview
- 12:30 – 12:45 "AWS’s HPC Solution update in 2026" by Kirti Devi (AWS, Global Head of Go-to-Market: HPC)
12:45 – 13:30 Panel Session "HPC and Cloud ~challenges and future vision ~" - Chair
- Carina Kemp
Global Academic Research Lead, Amazon Web Services (AWS) - Speaker

- Kirti Devi
- Head of Global HPC Go-To-Market
Amazon Web Services (AWS)
- Biography
- Kirti Devi is a dynamic and accomplished strategic leader with a track record of delivering business growth and innovation. With 15 + years of experience in business development, product management, and strategic alliances, Kirti has developed and executed strategies that deliver significant revenue and technological advancement in industry leading technology companies like HPE, Microsoft, and Intel across High Performance Computing (HPC), Artificial Intelligence (AI)-Machine Learning (ML) and Enterprise Software segments. In her current position at Amazon Web Services (AWS), Kirti leverages her extensive industry expertise to drive strategic vision and execution of HPC Go-to-Market (GTM) at global scale. With her customer-obsessed approach, Kirti leads the business development and solutions architecture teams to enable HPC customers’ AWS cloud journey. Beyond her professional accomplishments, Kirti is committed to societal impact, volunteering and supporting initiatives that
provide broader access to education for disadvantaged students.
- Panelist 1

- Rio Yokota
- Professor at Institute of Science Tokyo and leads the AI for Science Foundation Model Research Team at RIKEN.
- Biography
- Rio Yokota is a Professor at the Supercomputing Research Center, Institute of Science Tokyo, and leads the AI for Science Foundation Model Research Team at RIKEN Center for Computational Science. His research focuses on high performance computing and machine learning, and he received the Gordon Bell prize in 2009. He is the co-developer of Japanese LLMs Swallow and LLM-jp, and leads distributed training efforts on Japanese supercomputers.
- Panelist 2

- Worawan Diaz Carballo (Marurngsith)
- Assistant Professor of Computer Science at Thammasat University
- Biography
- Dr. Worawan Diaz Carballo (Marurngsith) is an Assistant Professor of Computer Science at Thammasat University, Lampang Campus, and the principal investigator of the HPC Ignite Initiative, a capacity-building research program supported by Thailand’s NRCT and ThaiSC. She holds a Ph.D. and M.Sc. in Informatics from the University of Edinburgh (UK) and a B.Sc. in Computer Science from Thammasat University.
Her research focuses on performance modeling and simulation of high performance computing systems, AI workload efficiency, and hybrid HPC AI convergence and cloud integration for education and applied innovation.
- Panelist 3

- Takuro Iizuka
- CTO at Fixstars Corporation
- Biography
- Takuro Iizuka is the CTO at Fixstars Corporation with over 15 years of performance engineering expertise spanning embedded systems to supercomputers, across GPUs, FPGAs, and AI accelerators. He leads the development of Fixstars' Performance Engineering products, including AIBooster—an AI workload acceleration platform adopted across automotive, broadcasting, and telecommunications. His work bridges the gap between cutting-edge AI models and production-ready infrastructure.
Tue, January 27, 2026 12:30 - 13:30 Room 1009
Title: GMO Internet & NVIDIA ~The Challenge of Optimizing Supercomputers for Commercial Services~
- Abstract
- In recent years, with the rapid growth of generative AI, the platforms used to develop and operate these technologies have drawn increasing attention. As users are presented with more options, selecting the right platform is no longer a matter of personal preference—it requires a careful balance of both cost and performance.
From the perspective of job scheduling in particular, it is essential to maximize overall system throughput by efficiently utilizing system resources while minimizing contention among users. GMO Internet, Inc. is working in collaboration with NVIDIA to not only deliver powerful computing resources but also focus on improving usability and enabling seamless access.
At the heart of this initiative is the ongoing tuning of our HPC environment and scheduling systems. In this session, we will introduce our approach to HPC optimization and share our efforts to support the success of our clients.
- Speaker 1

- Masafumi Ookawa
- GMO Internet, Inc.
Engineering Lead, Infrastructure Development, GMO GPU Cloud
- Biography
- Masafumi is an infrastructure engineer who plays a key role in developing a GPU cloud platform. With over 10 years of experience supporting the development and operation of enterprise systems at multiple software companies, he now leads the Infrastructure & Service Development Team at GMO Internet, Inc., where he has handled everything from designing core server infrastructure and implementing job schedulers to delivering solutions for customers.
His team provides a high-performance cloud platform tailored to the rapidly growing demand in generative AI and HPC, contributing significantly to the growth of Japan’s AI industry. Their technical efforts have gained widespread external recognition, with the following achievements:
November 2024|TOP500 (supercomputer performance)
Ranked 37th in the world and 6th in Japan. Achieved the top position among commercial cloud services in Japan.
June 2025|Green500
Ranked 34th globally and 1st in Japan, demonstrating superior power efficiency.
November 2025|ClusterMAX™ 2.0
Earned Japan’s first-ever “Silver” rating.
In addition, Masafumi is deeply committed to supporting clients in effectively utilizing AI workloads. His technical expertise and support have earned high praise from customers.
- Speaker 2

- Hiroshi Aiko
- NVIDIA Corporation
Senior Marketing Manager, Enterprise Marketing Department
- Biography
- Aiko began his career after graduating from university in the manufacturing industry, where he gained experience in the design, implementation, and operation of information systems and core network infrastructures. He later joined an IT solutions distributor, where he was responsible for technical support and failure analysis of storage networking products, while also overseeing the technical aspects of network infrastructure design and support for data center service providers.
He subsequently moved to a leading network equipment vendor, providing technical support and engaging in business development for OEM customers, as well as delivering system proposals and design support for clients in the financial and manufacturing sectors. Throughout his career, he has worked across a wide range of technologies—including storage networking (Fibre Channel), data center switches, and routing products—supporting customer system design and delivering technical expertise.
In 2017, he joined Mellanox Technologies, where he was involved in sales and marketing for HPC solutions. Following NVIDIA’s acquisition of Mellanox in 2020, he assumed his current role at NVIDIA. At NVIDIA, he primarily focuses on marketing activities related to HPC and networking technologies, while also leveraging his engineering background to clearly communicate the evolving infrastructure requirements and essential knowledge driven by AI and HPC, through technical articles and speaking engagements.
Tue, January 27, 2026 12:30 - 13:30 12F Conference Hall
Title: Toward Quantum Advantage: Quantum-Centric Supercomputing Software Architecture and Scientific Applications. / Data-Centric Architecture: Intelligent Data Acceleration and Content Awareness with IBM Storage Scale.
- Session Overview
- IBM Quantum’s Quantum-Centric Supercomputing (QCSC) software stack -- including Qiskit for HPC, HPC add-ons, workflow tools, and Slurm integration -- optimized for hybrid quantum-HPC development. We showcase applications in quantum simulation and chemistry using sample-based quantum diagonalization, error mitigation, and circuit/Hamiltonian optimization with HPC, enabled by QCSC-oriented development tools for debugging and testing.
IBM Storage Scale powers HPC and AI workloads with high-throughput, low-latency data access across hybrid environments. Its content-aware architecture integrates embedded compute, inferencing, and cataloging to reduce data movement. With protocol flexibility, encryption, and immutability, it transforms storage into a secure, intelligent platform optimized for scalable AI and HPC performance.
- Speakers
-

- Antonio Corcoles
- IBM Quantum
- “Towards large-scale Quantum-Classical computing”
- In this talk I will go over recent progress in software and capabilities for integrating large-scale quantum systems into modern supercomputing architectures. I will touch on new execution models for quantum, system performance, algorithms and applications updates, and integration software.
- Chris Maestas, CTO
- Data and AI Storage Solutions

Tue, January 27, 2026 13:30 - 15:00 Room 1002
Chair: Emil Vatai (RIKEN)
- 13:30 - 14:00
- "Integrating Quantum Software Tools with(in) MLIR"
- Patrick Hopf,Erick Ochoa Lopez,Yannick Stade,Damian Rovara,Nils Quetschlich,Ioan Albert Florea,Josh Izaac,Robert Wille,Lukas Burgholzer
- 14:00 - 14:30
- "The X Quantum Software Stack: Connecting End Users, Integrating Diverse Quantum Technologies, Accelerating HPC"
- Lukas Burgholzer, Jorge Echavarria, Patrick Hopf, Yannick Stade, Damian Rovara, Ludwig Schmid, Ercument Kaya, Burak Mete, Muhammad Nufail Farooqi, Minh Chung, Marco De Pascale, Laura Schulz, Martin Schulz, Robert Wille
- 14:30 - 15:00
- "QPU Micro-Kernels for Stencil Computation"
- Stefano Markidis,Luca Pennati,Gilbert Netzer,Marco Pasquale,Ivy Peng
Tue, January 27, 2026 13:30 - 15:00 Room 1008
Chair: Lingqi Zhang (RIKEN)
- 13:30 - 14:00
- "Optimization of a GEMM Implementation using Intel AMX"
- Yusuke Endo, Satoshi Ohshima, Takeshi Nanri
- 14:00 - 14:30
- "Guaranteed DGEMM Accuracy While Using Reduced Precision Tensor Cores Through Extensions of the Ozaki Scheme"
- Angelika Schwarz, Anton Anders, Cole Brower, Harun Bayraktar, John Gunnels, Kate Clark, RuQing G. Xu, Samuel Rodriguez, Sebastien Cayrols, Pawel Tabaszewski, Victor Podlozhnyuk
- 14:30 - 15:00
- "Towards Unified Acceleration: Weight-Stationary GEMM on HPC-oriented Elastic CGRAs"
- Chenlin Shi, Boma Adhi, Lin Teng, Jiaheng Liu, Shinobu Miwa, Kentaro Sano
Tue, January 27, 2026 13:30 - 16:00 Room 1004-1006
Accepted Posters: https://www.sca-hpcasia2026.jp/submit/accepted-posters.html
Explore as many as 154 posters and enjoy discussions with the authors.
During the poster session, coffee, tea, and light refreshments will be provided.
Posters will also be available for viewing on January 27 and 28 from 9:00 to 17:00.
Tue, January 27, 2026 13:30 - 17:00 Room 702
Contributors: Worawan Diaz Carballo (Thammasat University), Fabrizio Gagliardi (Barcelona Supercomputing Center)
Abstract: High-Performance Computing (HPC), once confined to elite research centers, is now becoming more accessible through cloud integration and shared infrastructure. This democratization creates opportunities, but access alone is not enough. Training and mentoring are crucial for transforming resources into solutions. The rise of AI and data-driven complexity means that even modest Proof-of-Concepts (POCs) demand substantial computational power. Global initiatives have responded by combining education with community-building. The ACM supports seasonal HPC Schools that offer intensive training and foster lasting professional networks. Simultaneously, the HPC-AI Advisory Council has organized competitions that bridge experts to newcomers on real-world problems. These efforts are enabled by support from HPC centers, such as RIKEN, NCI, BSC, and NSCC, which provide infrastructure and expertise, creating a pipeline that promotes skill development, broadens the scope of HPC education, and nurtures communities. Thailand’s HPC Ignite project, supported by NRCT and ThaiSC, inspired by these models, engaged 373 learners and produced 11 POCs addressing local challenges. It cannot succeed without clouds. With support from AWS, some POCs advanced toward deployment. This panel will explore how grassroots innovators can connect with global HPC and cloud ecosystems—highlighting the hybrid pathway as the key to sustainable, scalable, and equitable impact.
Program:
- 1:30–1:40
- Opening and Framing Talk: "Connecting Global HPC Infrastructure with Grassroots Innovation"
- Worawan Diaz Carballo & Fabrizio Gagliardi
- 1:40–2:00
- Talk 1: "Building HPC Education Pipelines: From ACM Seasonal Schools to Sustainable Communities"
- Fabrizio Gagliardi (Barcelona Supercomputing Center)
- 2:00–2:20
- Talk 2: "Bridging Continents: HPC Education from SC Leadership to Asian School Instruction"
- Bernd Mohr (Jülich Supercomputing Centre)
- 2:20–2:40
- Talk 3: "Bridging Experts and Newcomers: The Competition Model in Asia-Pacific"
- Qingchun Song (HPC-AI Advisory Council)
- 3:00–3:20
- Talk 4: "AI-HPC Convergence in Education: From Research Excellence to Grassroots Capacity Building"
- Mohammad Wahib (RIKEN R-CCS)
- 3:20–3:40
- Talk 5: "Coordinating International HPC Training: The Japanese Experience and Regional Integration"
- Kengo Nakajima (The University of Tokyo / RIKEN R-CCS)
- 3:40–4:00
- Talk 6: "From Supercomputers to Super Communities: Global–Local Collaboration for Inclusive Innovation"
- Worawan Diaz Carballo (Thammasat University)
- 4:00–4:50
- Panel Discussion: "Scaling Global-Local Collaboration: From Best Practices to Action"
- Moderators: Bernd Mohr & Fabrizio Gagliardi; Panelists: All speakers
- 4:50-5:00
- Closing Synthesis: "Building the Future Together: Action Items and Collaborative Pathways"
- Worawan Diaz Carballo
Tue, January 27, 2026 13:30 - 17:00 Room 802
Contributors: Tommaso Macrì, Ayumu Imai
Abstract: As quantum processors begin integrating with GPU/CPU supercomputers, HPC centers must chart a practical path from pilots to production. This invited session brings together QuEra (neutral-atom systems), Pawsey (Australia’s Quantum Supercomputing Innovation Hub), Deloitte Tohmatsu (enterprise consulting), LINKS Foundation (EU applied research) and Jij, Inc (Optimization Tooling/platform) to share lessons from real deployments and cross-regional initiatives. Topics include selecting “first-wave” use cases; dynamic scheduling and resource allocation for hybrid QC–HPC workflows; early benchmarking and verification; user support and training; and governance, security, and procurement models. Case insights include a hybrid ML pipeline that inserts a Quantum Reservoir Computing (QRC) layer executed on QuEra’s Aquila neutral-atom platform for credit-default prediction, and LINKS’ recent work on scheduler/allocator designs for hybrid clusters. The session closes with a moderated panel outlining an APAC–EU roadmap for 2026–2028 across algorithms, software stacks, and center operations to make quantum a standard tool in HPC.
Program:
- 13:30-13:40
- Welcome & framing: why hybrid QC-HPC now
- Chair (QuEra)
- 13:40-14:05
- Neutral-atom QPUs for HPC: Integration patterns & lessons from hybrid platforms
- Tommaso Macrì (Executive Account Manager, QuEra), Ayumu Imai (Country Manager, Japan, QuEra)
- 14:05-14:30
- Enabling hybrid workloads for researchers: Policies, workflows, and training
- Pascal Elahi (Quantum Supercomputing Researcher Lead, Pawsey Supercomputing Research Centre)
- 14:30-14:55
- Hybrid Tooling: Accelerating QAOA/QRAO in hybrid stacks
- Yu Yamashiro (CEO, Jij Inc)
- 14:55-15:15
- Tea break
- 15:15-15:40
- Case study: Scheduler/allocator designs for hybrid clusters + credit-default prediction application example
- Paolo Viviani (Advanced Computing, Photonics and Electromagnetics Research Domain, Fondazione LINKS), Giacomo Vitali (Advanced Computing, Photonics and Electromagnetics Research Domain, Fondazione LINKS)
- 15:40-16:05
- From pilots to value: An enterprise readiness lens for quantum+HPC
- Kenji Sugisaki (Senior Consultant, Deloitte Tohmatsu)
- 16:05-16:40
- Panel: Benchmarks, SLAs, and roadmaps (2026–2028) for APAC–EU HPC centers
- QuEra · Pawsey · Jij · LINKS · Deloitte Tohmatsu
- 16:40-17:00
- Audience Q&A + “first 100-days” center-readiness checklist
- All speakers
Tue, January 27, 2026 13:30 - 17:00 Room 1007
Contributors: Tatsuhiro Chiba, Hiroshi Horii
Abstract: The emergence of Quantum Computing and Artificial Intelligence (AI) is reshaping industries and redefining the boundaries of what is computationally possible. These two transformative technologies are not only advancing independently but are also beginning to converge, offering unprecedented opportunities to solve complex problems across domains.
As Quantum and AI technologies mature, real-world use cases are evolving rapidly in the various domains, material sciences, financial modeling, physics, logistics, and so on. Quantum and AI have distinct strengths and operate in different computational paradigms; Quantum excels in solving combinatorial and probabilistic problems, while AI has an advantage to the data-driven inference. Their complementary nature enables a synergistic foundation for next-generation computing.
This half-day workshop brings together leading voices from academia, industry, chip vendors, and cloud providers to explore how Quantum systems and AI systems are being applied to the real-world use cases today and how they can shape the future of high-performance computing. The session will feature domain-specific case studies, technical presentations, and infrastructure insights for Quantum system and AI system. The workshop will organize a forward-looking panel discussion focused on designing a converged compute fabric, that integrates Quantum and AI capabilities to co-exist and co-evolve.
Program:
- 13:30-13:40
- Opening Remark
- Tatsuhiro Chiba (IBM)
- 13:40-14:05
- Accelerating Toward Quantum Advantage Together
- Ryuki Tachibana (IBM)
- 14:05-14:30
- HPC–QC for “Quantum” Insights into Chemical Phenomena
- Yuuya Oonishi (JSR)
- 14:30-14:55
- The Sovereignty Dilemma: Bridging the Gap between Agile GPU Farms and Tier 3+ Reliability
- Yasuhiro Araki (Sakura Internet)
- 15:00-15:30
- Tea Break
- 15:30-15:55
- Fixstars Amplify: Showcasing the Practical Value of Ising Machines
- Akihiro Asahara (Fixstars)
- 15:55-16:20
- Next-Generation Materials Design with Generative AI and Quantum Computing: The Promise of the Generative Quantum Eigensolver
- Qi Gao (Mitsubishi Chemical)
- 16:20-16:55
- Panel Discussion
- 16:55-17:00
- Closing
Tue, January 27, 2026 13:30 - 17:00 Room 801
Contributors: Mohan Kalkunte (Broadcom), TBC (Arista)
Abstract: The rapid growth of AI model sizes has shifted system bottlenecks from compute to communication, making interconnect scalability and efficiency critical for training performance. As single accelerators reach their architectural limits, large-scale GPU clusters increasingly depend on high-bandwidth, low-latency, and well-managed fabrics that can operate reliably at multi-thousand-node scale.
This work examines recent advances that position Ethernet as a viable interconnect for both AI scale-out and emerging scale-up environments. We present two key technologies—Scale-Up Ethernet Transport (SUE-T) and the Ethernet for Scale-Up Networking (ESUN)—along with complementary enhancements in congestion control, lossless operation, telemetry, and automated fabric management. Together, these capabilities enable Ethernet to meet requirements traditionally associated with specialized or proprietary interconnects.
The session includes deployment insights from hyperscale clusters, focusing on operational behavior, performance characteristics, and scalability considerations. We also highlight ecosystem support from leading OEM partners such as Arista. Academic contributors provide additional analysis on Ethernet’s applicability to AI scale-up and HPC workloads, identifying opportunities for future research and standardization.
Program:
- 13:30-13:50
- "Next-Gen Ethernet Solutions for AI Scale-Up/Scale-Out Workloads"
- Mohan Kalkunte (Broadcom)
- 13:50-14:30
- "Tomahawk Ultra - Redefining Ethernet Switching for AI and HPC"
- Niranjan Vaidya (Broadcom)
- 14:30-15:00
- "AI Networkng Architecture"
- Koichi Hyodo (Arista)
- 15:00-15:30
- Break
- 15:30-16:00
- "Emerging Technologies and Future Architecture Improvement Potential in HPC/AI Interconnects"
- Yuichiro Ajima (Fujitsu)
- 16:00-16:30
- "High-Performance and Scalable Middleware for HPC and AI"
- Dr Panda (The Ohio State University)
- 16:30-17:00
- "Scalable Collective Operations: Reducing Global Traffic and Avoiding Congestion"
- Daniele De Sensi (Sapienza Univ of Rome)
Tue, January 27, 2026 15:30 - 17:00 Room 1002
Chair: Joao Batista (RIKEN)
- 15:30 - 16:00
- "Design of a Superposition-Based Approximate QRAM for Noise-Tolerant Quantum Machine Learning"
- Sohrab Sajadimanesh, Ehsan Atoofian
- 16:00 - 16:30
- "Deterministic Quantum Search for Index Retrieval: Algorithm Design and Implementation"
- Harishankar Mishra, Asvija Balasubramanyam, Gudapati Naresh Raghava
- 16:30 - 17:00
- "Deep Learning-Integrated Pairwise-Qubit Subsystems for Highly Efficient Quantum Circuit Simulation"
- Santana Yuda Pradata, Muhammad Alfian Amrizal, Wiwit Suryanto, Ahmad Ridwan Tresna Nugraha, Hiroyuki Takizawa
Tue, January 27, 2026 15:30 - 17:00 Room 1008
Chair: Jens Domke (RIKEN)
- 15:30 - 16:00
- "Improved Implementation of Number Theoretic Transform on NVIDIA GPU with Tensor Cores"
- Yukimasa Sugizaki, Daisuke Takahashi
- 16:00 - 16:30
- "Tensor-Core-Optimized Strategies for BLR × Tall-Skinny Matrix Multiplication in BEM"
- Akihiro Ida, Kazuya Goto, Rio Yokota, Tasuku Hiraishi, Toshihiro Hanawa, Takeshi Iwashita, Masatoshi Kawai, Satoshi Ohshima, Tetsuya Hoshino
- 16:30 - 17:00
- "Mixed-precision Interpolative Decomposition on GPUs" [Best Paper Finalist]
- Qianxiang Ma, Toshiyuki Imamura
Tue, January 27, 2026 15:30 - 18:00 Room 1003
Contributors: Howard Weiss, Brian Christiansen
Tue, January 27, 2026 17:00 - 18:00 Room 702
Contributors: Jack Jones, Adolfy Hoisie, Artur Podobas, Filippo Spiga, Ron Brightwell, Yukinori Sato
Tue, January 27, 2026 17:00 - 18:00 Room 1008
Contributors: Alex Upton, Bjoern Enders
Tue, January 27, 2026 17:00 - 18:00 Room 1002
Contributors: Nicolas Erdody, Rio Yokota
Tue, January 27, 2026 17:00 - 18:00 Room 1007
Contributors: Lena Oden, Kenji Doya
Tue, January 27, 2026 17:00 - 18:00 Room 801
Contributors: Marwa Farag
Tue, January 27, 2026 16:30 - 18:00 Room 1101
Contributors: Julie Ma, Masahiro Nakao, Emily Moffat Sadeghi
Tue, January 27, 2026 17:00 - 18:00 Room 802
Contributors: Julie Faure-Lacroix, Eugene Low, Suzanne Talon
Tue, January 27, 2026 18:30 - 20:00 RIHGA Royal Hotel
Venue: 3F Korin-no-ma, RIHGA Royal Hotel Osaka
The banquet venue is located right next to the conference venue (connected by a walkway).
Eligibility:
The banquet is open to participants holding a Conference Pass or Student Pass.
Exhibitor Pass holders are also eligible if their pass was issued as part of a sponsor package, in which case “Banquet” will be printed on the pass.
Participants who have purchased a Banquet Pass are also eligible to attend.
For details, please refer to the pass benefit information.
Tue, January 27, 2026 9:30 - 17:00
Wed, January 28, 2026 9:00 - 17:00
Thu, January 29, 2026 9:00 - 15:30
Venue: 3F Event Hall
Exhibitor List:
Nearly 100 exhibitors will showcase their latest technologies, products, and research results. Please see the exhibitor list and floor map below.
Exhibitor List and Floor Plan (PDF)
Exhibitors Forum:
During the exhibition hours, exhibitors will deliver 15-minute presentations. Please see the detailed program below.
Exhibitors Forum
Wed, January 28, 2026 09:00 - 09:45 5F Main Hall
Session Chair: Satoshi Matsuoka (RIKEN)

Speaker
- Hiroaki Kitano
- President & CEO, Sony Computer Science Laboratories (Sony CSL), Japan
Professor, Okinawa Institute of Science and Technology (OIST), Japan
Biography
Hiroaki Kitano is President and CEO of Sony Computer Science Laboratories, Inc. (Sony CSL). Kitano joined Sony CSL as a researcher in 1993 and has served as President and CEO since 2011. He served as Chief Technology Officer of Sony Group Corporation from 2022 to 2024 and has been Chief Technology Fellow since 2025.
As a researcher at Carnegie Mellon University, Kitano built large-scale data-driven AI systems on massively parallel computers, for which he received the Computers and Thought Award from IJCAI. At Sony CSL and California Institute of Technology, he pioneered the field of systems biology.
Outside Sony, Kitano is a member of the OECD Expert Group on AI Futures, Japan’s AI Strategy Council and AI Safety Institute. Within academia, he serves as a professor at Okinawa Institute of Science and Technology (OIST). He is the Founding President of RoboCup Federation. In 2021, Kitano established the Nobel Turing Challenge, a grand challenge to develop a new engine for scientific discovery.
Abstract
Creating fully or highly autonomous AI and robotics systems to perform high-caliber scientific research will be the most important scientific accomplishment (1). The Nobel Turing Challenge is a grand challenge aiming at building AI scientists capable of making major scientific discoveries continuously at the level worthy of Nobel Prizes (2). The WARP Drive for scientific discoveries shall be created, initially based on the idea of Trillions of data, billions of hypotheses, millions of experiments, and thousands of discoveries. Establishing the cycle of massive extraction of knowledge, massive hypothesis generation, massive experiments by robotics, and massive verification and knowledge consolidation, is the critical first step. This approach is a total flip of conventional wisdom of how science can be performed. Rather than trying to ask an important question, AI scientists may ask every question and important answers are there to be discovered. Massive computing power to enable AI capabilities combined with sophisticated robotics systems for high-precision experiments are the key to the success.
- Kitano, H. (2016) Intelligence to Win the Nobel Prize and Beyond: Creating the Engine for Scientific Discovery. AI Magazine37(1)
- Kitano, H. Turing Challenge: creating the engine for scientific discovery. npj Syst Biol Appl 7, 29 (2021). https://doi.org/10.1038/s41540-021-00189-3
Wed, January 28, 2026 09:45 - 10:30 5F Main Hall
Session Chair: Hiroyuki Takizawa (Tohoku University)

Speaker
- Mateo Valero
- Director/Professor
Barcelona Supercomputing Center, Spain
Biography
Mateo Valero, http://www.bsc.es/cv-mateo/ is professor of Computer Architecture at Technical University of Catalonia (UPC) and is the Founding Director of the Barcelona Supercomputing Center, where his research focuses on high performance computing architectures. He has published approximately 700 papers, has served in the organization of more than 300 International Conferences and has given more than 800 invited talks. Prof. Valero has been honored with numerous awards, among them: The Eckert-Mauchly Award 2007 by IEEE (Institute of Electrical and Electronics Engineers) and ACM (Association for Computing Machinery), the Seymour Cray Award 2015 by IEEE and the Charles Babbage 2017 by IEEE. Among other awards, Prof. Valero has received The Harry Goode Award 2009 by IEEE, The Distinguished Service Award by ACM. Prof. Valero is a "Hall of the Fame" member of the ICT European Program (selected as one of the 25 most influential European researchers in IT during the period 1983-2008, Lyon, November 2008).
For the full biography, please see Prof. Mateo Valero's CV.
Abstract
The leitmotif of my talk will be the thesis that past advances in computer architecture continue to be relevant in our field today and will dictate the future. In that context, I will touch upon how the current AI accelerators are based on the systolic arrays, how the long vector processors of today are influenced by Cray supercomputers, and how past architecture ideas to support different data formats are reused for mixed precision support in HPC and for layer-by-layer optimization of energy-efficient AI accelerators. This talk will describe some of the related contributions of UPC Department of Computer Arcthiecture (DAC) to the scientific community, especially in the fields of superscalar and vector processors. I will briefly discuss specific UPC DAC contributions which have been incorporated into current high-performance processors, including supercomputers and accelerators aimed at efficient execution of AI applications. In the second part of my talk, I will describe the current research topics at the Barcelona Supercomputing Center (BSC), as well as the chips designed at BSC. Finally, I will conclude with our future vision of how Europe can develop competitive chips based on RISC V to be used in the design of supercomputers and accelerators for AI in the coming years.
Wed, January 28, 2026 11:00 - 12:30 12F Conference Hall
Contributors: Addison Snell (Intersect360 Research)
Abstract: Following the success and popularity of the “Fishbowl Panel” at ISC, we look forward to bringing the format to SCA / HPCAsia 2026. This panel will explore the disruptions and revolutions facing HPC and AI, seeking to separate out the true innovations and advancements from what is myth, hype, or marketing. This forward-looking panel is designed to elicit opinions from a wide range of industry thought leaders. Every eight minutes, one of the three panelists will be dismissed, replaced by a willing member of the audience. Respectful disagreement and diversity of opinions is encouraged. Welcome to the Fishbowl.
Wed, January 28, 2026 11:00 - 12:30 Room 1002
Chair: Masado Ishii (RIKEN)
- 11:00 - 11:30
- "Enhancing Stability and Optimizing Implmentation of Mixed-Precision Block $\epsilon$-Circulant Preconditioned Solvers for Parallelization-in-Time"
- Ryo Yoda, Matthias Bolten
- 11:30 - 12:00
- "Task-decomposed Overlapped Preconditioner for Sustained Strong Scalability on Accelerated Exascale Systems"
- Niclas Jansson, Martin Karp, Szilard Pall, Stefano Markidis, Philipp Schlatter
- 12:00 - 12:30
- "A Matrix-Free Algebraic hp-Multigrid Method for Computational Fluid Dynamics Applications" [Best Paper Finalist]
- Peter Ohm, Graham Harper, Niclas Jansson
Wed, January 28, 2026 11:00 - 12:30 Room 1008
Chair: Artur Podobas (KTH)
- 11:00 - 11:30
- "Beyond Exascale: Dataflow Domain Translation on a Cerebras Cluster" [Best Paper Finalist]
- Tomas Oppelstrup, Nicholas Giamblanco, Delyan Z. Kalchev, Ilya Sharapov, Mark Taylor, Dirk Van Essendelft, Sivasankaran Rajamanickam, Michael James
- 11:30 - 12:00
- "GPU Partitioning, Power, and Performance of the AMD MI300A"
- Amr Abouelmagd, David Boehme, Stephanie Brink, Jason Burmark, Michael McKinsey, Anthony Skjellum, Olga Pearce
- 12:00 - 12:30
- "What Will the Grace Hopper-Powered Jupiter Supercomputer Bring for Sparse Linear Algebra?"
- Yu-Hsiang Tsai, Mathis Bode, Hartwig Anzt
Wed, January 28, 2026 11:00 - 12:30 Room 1009
Chair: Aleksandr Drozd (RIKEN)
- 11:00 - 11:30
- "Performance analysis of Arm-based processors across multiple compilers for HPC workloads"
- Chigusa Kobayashi, Kazuto Ando, Tsuyoshi Yamaura, Hikaru Inoue, Hitoshi Murai
- 11:30 - 12:00
- "Cloud-Hardware Co-Design for Memory Bandwidth-Bound HPC Workloads: Performance and Characteristics of Azure HBv5 Virtual Machines"
- Amirreza Rastegari, Sai Kovouri, Michael Cui, Zehra Naz, Jay Fleischman, Saurabh Gupta, Anil Harwani, Gabriel H. Loh, Joe Greenseid, Evan Burness, Prabhat Ram, Michael F. Ringenburg
- 12:00 - 12:30
- "Modeling the Potential of Message-Free Communication via CXL.mem"
- Stepan Vanecek, Matthew Turner, Manisha Gajbe, Matthew Wolf, Martin Schulz
Tue, January 27, 2026 11:30 - 17:00 Room 1001
Wed, January 28, 2026 11:00 - 17:00 Room 1001
Contributors: Taisuke Boku (University of Tsukuba), Andrew Rohl (National Computational Infrastructure (NCI), the Australian National University (ANU))
Abstract: As AI reshapes the global research and innovation landscape, national supercomputing centers across the Asia-Pacific and the world are evolving rapidly to meet new demands. Building on five years of dialogue through the SCAsia HPC Centre Leaders Forum and the growing collaboration within the Alliance of Supercomputing Centres (ASC), this session proposes the establishment of a dedicated HPC Centers Forum at SCAsia/HPCAsia 2026. Co-chaired by Taisuke Boku (Center for Computational Sciences, University of Tsukuba, Japan) and Andrew Rohl (National Computational Infrastructure, the Australian National University, Australia), the session will showcase how HPC centers across the region are pivoting in response to AI—reimagining infrastructure architectures, adapting research workflows, refining service delivery models, evolving resource allocation strategies, and engaging new user communities. The session will feature a curated selection of short presentations from regional HPC leaders, highlighting center-level strategies and national policy drivers. We will share the insights, cross-center learning, and discussion of future collaboration opportunities across APAC and the world. The HPC Centers Forum aims to become a recurring feature of SCAsia/HPCAsia, reinforcing regional leadership, enabling collective action, and fostering a coordinated response to the global HPC, AI and more convergence challenge.
Program:
Day 1, Jan 27 (Tue):
- 11:30-11:50
- Information Initiative Center
- Takeshi Fukaya (Hokkaido University)
- 11:50-12:10
- Cyberscience Center
- Hiroyuki Takizawa (Tohoku University)
- 12:10-12:30
- Center for Computational Sciences
- Taisuke Boku (University of Tsukuba)
- 12:30-13:30
- Lunch
- 13:30-14:00
- European High Performance Computing Joint Undertaking
- Anders Jensen (EuroHPC JU)
- 14:00-14:20
- Korea Institute of Science and Technology Information
- Chan-Yeol Park (KISTI)
- 14:20-14:40
- Argonne National Laboratory
- Brice Videau (ANL)
- 14:40-15:00
- National Supercomputing Centre Singapore
- Terence Hung (NCCS Singapore)
- 15:00-15:30
- Break
- 15:30-15:50
- National Institute of Informatics
- Kento Aida (NII)
- 15:50-16:10
- Joint Usage/Research Center for Interdisciplinary Large-scale Information Infrastructures
- Takumi Honda (University of Tokyo)
- 16:10-16:30
- D3 Center
- Susumu Date (University of Osaka)
- 16:30-17:00
- RIKEN Center for Computational Science
- Satoshi Matsuoka (R-CCS)
Day 2, Jan 28 (Wed):
- 11:00-11:30
- Lawrence Livermore and Oakridge National Laboratories
- Bronis R. de Supinski (LLNL)
- 11:30-11:50
- National Computational Infrastructure and Pawsey Supercomputing Research Centre
- Andrew Rohl (ANU)
- 11:50-12:10
- Jülich Supercomputing Centre
- Bernd Mohr (JSC)
- 12:10-12:30
- Swiss National Computing Centre
- Thomas Schulthess (CSCS)
- 12:30-13:30
- Lunch
- 13:30-13:50
- Information Technology Center
- Kengo Nakajima (University of Tokyo)
- 13:50-14:10
- Supercomputing Research Center/Center for Information Infrastructure
- Toshio Endo (Institute of Science Tokyo)
- 14:10-14:30
- Information Technology and Human Factors
- Ryousei Takano (National Institute of Advanced Industrial Science and Technology)
- 14:30-14:50
- Research Institute for Information Technology
- Kazuki Yoshizoe (Kyushu University)
- 15:00-15:30
- Break
- 15:30-15:50
- Texas Advanced Computing Center
- Dan Stanzione (University of Texas)
- 15:50-16:10
- IT Center for Science
- Kimmo Koski (CSC)
- 16:10-16:30
- National Center for High-performance Computing
- Weicheng Huang (NCHC)
- 16:30-16:50
- Bristol Centre for Supercomputing
- Sadaf Alam (BriCS)
Wed, January 28, 2026 11:00 - 17:00 Room 1102
Contributors: Ryosuke Murayama (R-CCS), Earl Joseph (Hyperion Research), Debra Goldfarb (Amazon Web Services)
Abstract: High-performance computing (HPC), increasingly combined with AI and cloud-scale resources, is becoming a critical enabler for addressing complex global challenges. This invited session will examine how advanced computational capabilities are transforming the ways governments, researchers, and industries design solutions for public health, environmental resilience, and sustainable development. Through international perspectives spanning science, economics, and platform innovation, the session will highlight how integrated HPC–AI ecosystems are accelerating evidence-based decision-making and expanding access to advanced computing resources. Presentations will cover data-driven methodologies for understanding societal risks, the economic value of HPC for national and industrial competitiveness, and new models of collaboration that connect global research communities with next-generation infrastructure providers. By bringing together leaders from academia, industry, and policy circles, the session aims to articulate a shared view of how HPC and AI contribute to inclusive, resilient, human-centered digital societies. The discussion also situates these developments within broader global efforts—including Japan’s Society 5.0 vision—to link technological capability with societal benefit.
Program:
- 11:00-11:01
- Outline of the session by Ryosuke Murayama
- 11:01-12:40
- Track 1: Societal Impact of HPC & AI, co-chaired by Earl Joseph
- Introduction by Earl Joseph
- [Presentations]
- Makoto Tsubokura (R-CCS)
- Anders Dam Jensen (EuroHPC JU)
- Nobuyasu Ito (R-CCS)
- Takane Hori (JAMSTEC)
- 12:40-13:30
- Lunch Break
- 13:30-16:25
- Track2: HPC-Enabled Modeling of Climate and Human-System Risks, co-chaired by Debra Goldfarb
- Introduction by Debra Goldfarb
- [Presentations]
- Masahiro Kazumori (Japan Meteorological Agency)
- Giacomo de Nicola (Harvard T.H.Chan School of Public Health)
- Preetha Rajaraman (Radiation Effects Research Foundation)
- Francesca Dominici (Harvard Data Science Initiative)
- Note:
15:20-15:40 Short-break
16:15-16:25 Small Layout change for Panel & Wrap up - 16:25-17:00
- Short Panel & Warp up for both tracks by Ryosuke Murayama, Earl Joseph & Debra Goldfarb
Tue, January 27, 2026 11:30 - 17:00 Room 1202
Wed, January 28, 2026 11:00 - 17:00 Room 1202
Contributors: Rio Yokota, Charlie Catlett
Abstract: The TPC is a global initiative that brings together scientists from government laboratories, academia, research institutes, and industry to tackle the immense challenges of building large-scale AI systems for scientific discovery. By focusing on the development of massive generative AI models, the consortium aims to advance trustworthy and reliable AI tools that address complex scientific and engineering problems. Target community includes (a) those working on AI methods development, NLP/multimodal approaches and architectures, full stack implementations, scalable libraries and frameworks, AI workflows, data aggregation, cleaning and organization, training runtimes, model evaluation, downstream adaptation, alignment, etc.; (b) those that design and build hardware and software systems; and (c) those that will ultimately use the resulting AI systems to attack a range of problems in science, engineering, medicine, and other domains.
Website: https://tpc.dev/tpc-track-at-sca-hpca26/
Program:
Day 1, Jan 27 (Tue)
- 11:30-12:30
- Session 1.1: TPC International Collaborative Initiatives
- Workshop Welcome and Overview (Rio Yokota (IST), Charlie Catlett (Argonne))
- Open Frontier Model: Rio Yokota (IST)
- Evaluation: Franck Cappello (Argonne)
- Agentic AI and Scientific Discovery: Robert Underwood (Argonne)
- Driving Applications: Valerie Taylor (Argonne)
- 12:30-13:30
- Lunch Break
- 13:30-15:00
- Session 1.2: TPC Vision and Strategies (Moderator: Rio Yokota, Institute of Science Tokyo/RIKEN)
- The Transformational AI Models Consortium (ModCon): Neeraj Kumar (PNNL)
- EuroTPC: Fabrizio Gagliardi (BSC)
- Collaborations in AI4S – Now and Future: Satoshi Matsuoka (RIKEN)
- U.S. Department of Energy Genesis Mission: Rick Stevens (Argonne)
- 15:00-15:30
- Break
- 15:30-17:00
- Session 1.3: Selected TPC Technical Working Group Updates (Moderator: Charlie Catlett, ANL/UChicago)
- AI for Life Sciences and Healthcare: Makoto Taiji (RIKEN)
- Toward Next-Generation Ecosystems for Scientific Computing: Workshop Summary: Anshu Dubey (Argonne)
- AI for Drug Discovery: Arvind Ramanathan (Argonne)
- Panel
Day 2, Jan 28 (Wed)
- 11:00-12:30
- Session 2.1: AI for Science (Moderator: Neeraj Kumar, PNNL)
- Evaluation of Geospatial Foundation Models: Kyoung-Sook Kim (AIST)
- Vision Foundation Models for Weather and Climate Downscaling: Mohamed Wahib (RIKEN)
- LUMI AI Factory – for Science and Business: Pekka Manninen (CSC)
- When Language Models Learn from Themselves: Synthetic Data and Scientific Knowledge: Javier Aula-Blasco (BSC)
- 12:30-13:30
- Lunch Break
- 13:30-15:00
- Session 2.2: Agentic AI
- Agentic Large Language Model Copilots for Scientific Workflows: Anurag Acharya (PNNL)
- Agentic AI vs ML-based Autotuning: A Comparative Study for Loop Reordering Optimization: Khaled Ibrahim (LBNL)
- Breaking Barriers in Science: The AI and Hybrid Computing Evolution: Thierry Pellegrino (AWS)
- System Requirements for Scalable Agentic AI: Ian Foster (ANL)
- 15:00-15:30
- Break
- 15:30-17:00
- Session 2.3: Inference Services (Moderator: Anurag Acharya, PNNL)
- Secure AI Infrastructure for Scientific Computing and Applications: Jens Domke (RIKEN)
- VibeCodeHPC: Takahiro Katagiri (Nagoya University)
- The TPC Academic Scientific Inference Group: Perspectives from Around the World: Dan Stanzione (TACC)
- Daria Soboleva (Cerabras): Mixture of Experts at Scale on Cerebras Hardware
Wed, January 28, 2026 11:00 - 17:50 Room 1003
Contributors: Mitsunori Ikeguchi (RIKEN R-CCS)
Abstract: The 8th R-CCS International Symposium will be held to discuss the outlook from Fugaku to FugakuNEXT and cutting-edge academic research on future-oriented computer science and computational science, including AI technology.
Website: https://www.r-ccs.riken.jp/R-CCS-Symposium/2026/
Program:
- 11:00-11:10
- Opening & MOU Signing Ceremony between IHPC/NSCC and RIKEN R-CCS
- Mitsunori Ikeguchi (RIKEN R-CCS)
- 11:10-12:30
- Session-1: ”FugakuNEXT: HPC Applications”
- Session Chair: Yasumichi Aoki (RIKEN R-CCS)
- 12:30-13:30
- Lunch Break
- 13:30–15:00
- Session-2: ”FugakuNEXT: AI for Science”
- Session Chairs: Rio Yokota (Science Tokyo/RIKEN R-CCS), Mohamed Wahib (RIKEN R-CCS)
- 15:00-15:30
- Break
- 15:30–16:20
- Overview
- Satoshi Matsuoka (RIKEN R-CCS)
- 16:20–17:50
- Session-3: ”FugakuNEXT: Systems”
- Session Chair: Masaaki Kondo (RIKEN R-CCS)
- 17:50
- Closing
- Mitsunori Ikeguchi (RIKEN R-CCS)
- 18:15–20:00
- Reception
Wed, January 28, 2026 12:30 - 13:30 Room 1001
Title: Next Vector project based on proven NEC Vector and RISC-V architecture
- Speaker
- Shintaro MOMOSE, Ph.D., NEC HPC Department
Wed, January 28, 2026 12:30 - 13:30 Room 1002
Title: Fluid Management in Technology Cooling Systems, Coolant Distribution Units & the importance of cleanliness in liquid cooled architecture.
- Summary of the Session
- Effective Fluid Management is mandatory: the CDU (Coolant Distribution Unit) acts as the system's "heart" (flow control) and "kidney" (filtration), isolating the high-purity TCS loop from facility water. Before connecting IT gear, rigorous pre-commissioning cleaning and filtration staging are non-negotiable to protect assets and ensure optimal energy efficiency. The CDU must continuously monitor fluid chemistry (pH, conductivity) to prevent corrosion and system failure.
- Speaker

- Matt Archibald
- Biography
- Matt Archibald is the Director of Technical Architecture at nVent supporting the data center and networking space. Matt is deeply focused on liquid cooling (close-coupled and direct-to-chip), unified infrastructure management, data center monitoring, and automated data center infrastructure management. Previously, Matt was the Global Installation & Planning Architect for Lenovo Professional Services and spent over 15 years in the data center space. Previous to this, Matt worked as a development engineer in the IBM System x and BladeCenter power development lab doing power subsystem design for BladeCenter and System x servers. Matt holds over 100 patents for various data center and hypervisor technologies. Matt has four degrees from Clarkson University in Computer Engineering, Electrical Engineering, Software Engineering, and Computer Science and a Bachelor of Engineering in Electronics Engineering from Auckland University of Technology.
Wed, January 28, 2026 12:30 - 13:30 Room 1008
Title: Accelerating AI-driven scientific discovery with supercomputing
- Synopsis
- AI is rapidly accelerating in scientific fields to revolutionize research and power a new era of innovation. To speed time-to-value, scientists and researchers need specialized infrastructure, software and services to build robust and reliable models, and do efficiently. This session will explore how supercomputing has become foundational to deliver significant compute performance and strong scaling capabilities to support a new generation of AI model development and training requirements. Hear how organizations are turning to fully integrated high-performance computing (HPC) systems to support their AI-driven research to increase predictability, accelerate discovery and solve some of humanity’s most complex challenges.
- Speaker

- Trish Damkroger
- Senior Vice President and General Manager, HPC & AI
- Biography
- Trish Damkroger is the Senior Vice President and General Manager for the HPC & AI Infrastructure Solutions business at Hewlett Packard Enterprise. In this role, she leads the end-to-end high-performance computing business from product concept through end of life support, which includes AI systems targeted at large-scale model building. Trish brings more than 30 years of HPC leadership and expertise within public and private sectors. Prior to joining HPE, Trish was Vice President and General Manager of the HPC group at Intel where she led strategic initiatives to deliver compute, accelerators and memory optimized for supercomputers, including exascale-class systems. She was also the Deputy Associate Director of Computation at the U.S. Department of Energy’s Lawrence Livermore National Laboratory (LLNL) where she led a group of more than 1,000 engineers and scientists focused on supercomputing efforts. Trish holds a Bachelor of Science degree in Electrical Engineering from the California Polytechnic State University and a Master of Science degree in Electrical Engineering from Stanford University.
Wed, January 28, 2026 12:30 - 13:30 Room 1009
- Speaker

- Tony Gaunt
- Vice President, Product Management, Asia
- Biography
- Tony Gaunt is the Vice President of Product Management for Asia at Vertiv, where he leads the development and execution of product strategies across Southeast Asia, Australia and New Zealand, South Korea, and Japan. In this strategic role, Tony works to align Vertiv’s product innovation with evolving customer needs, helping to accelerate growth and enhance value delivery across one of the company’s most dynamic regions.
Prior to assuming this role, Tony served as Vice President for Sales, Asia, where he oversaw all commercial operations across key markets and played a pivotal role in building a world-class sales organization. His leadership focused on go-to-market strategies across both direct and channel segments, powered by Vertiv’s broad portfolio of trusted infrastructure solutions.
Tony also previously held the role of Vice President for Colocation and Hyperscale for 12 years, driving Vertiv’s success in the Multi-Tenant Data Centre and Cloud Hyperscale sectors across ANZ, Asia, and India. With over 27 years of experience in the data center industry spanning the UK, Europe, Australia, and Asia, Tony is recognized as a seasoned sales and product leader with deep expertise in mission-critical infrastructure.
A frequent industry speaker and contributor to Tier 1 publications and Vertiv thought leadership, Tony is a respected voice in the data center community. He also serves as a Board Member of the Infrastructure Masons Australia chapter.
Tony holds a Master’s Degree in Management from the Macquarie Graduate School of Management in Australia. He is passionate about cultivating strong industry relationships, mentoring the next generation of leaders, and driving innovation that supports customer success across the region.
Wed, January 28, 2026 12:30 - 13:30 12F Conference Hall
Title: HPC-Quantum Hybrid Computing
Speaker: Ross Duncan, Head of Quantum Software
Wed, January 28, 2026 12:30 - 13:30 Room 1202
Title: Advanced Cooling and Power Solutions for Overcoming HPC Barriers
- Session Overview
- Advanced Cooling and Power Solutions for Overcoming HPC Barriers
As HPC and AI infrastructure are becoming a core of digital infrastructure, there are still a lot of gaps in the current infrastructures for these applications. MHI is working to resolve these issues from data center infrastructure development standpoint.
A lot of research and technology development have already been done regarding HPC, however, when it comes to social implementation, variety of issues such as grid power capacity, water utilization, cooling & heat recovery, renewable integration are emerging.
As a One Stop Solution Provider, MHI is approaching these `upcoming issues` by developing solutions that combine advanced cooling and power technologies. MHI recognizes the gap between research and social implementation and making efforts to realize sustainable infrastructure through collaboration between academia and industry.
Speakers

- Akira Fujita, P.E. Jp (Elec.), Director
- Electrification System Group
Data Center & Energy Management Department
Growth Strategy Office
Mitsubishi Heavy Industries, Ltd.

- Hisashi Nakaya, Director
- Data Center Design & Engineering Group
Data Center & Energy Management Department
Growth Strategy Office
Mitsubishi Heavy Industries, Ltd.

- Kewal Dharamshi, Program Manager
- SDX Team
Data Center & Energy Management Department
Growth Strategy Office
Mitsubishi Heavy Industries, Ltd.
Wed, January 28, 2026 13:30 - 15:00 Room 1002
Chair: Zhengyang Bai (RIKEN)
- 13:30 - 14:00
- "Toward unprivileged, portable and generic network topology discovery"
- Thibaut Pepin, Julien Jaeger, Guillaume Mercier, Brice Goglin
- 14:00 - 14:30
- "Revisiting Communication Software Offloading for MPI+Threads: Reducing Contention and Improving Overlap on Many-Core Systems"
- Sergej Breiter, Minh Chung, Karl Furlinger, Josef Weidendorfer, Dieter Kranzlmüller
- 14:30 - 15:00
- "Rankmap optimization for large scale HPC applications with simulated annealing based on MPI trace information"
- Akiyoshi Kuroda, Yoshifumi Nakamura, Kazuto Ando, Hitoshi Murai, Chisachi Kato
Wed, January 28, 2026 13:30 - 15:00 Room 1008
Chair: Robert Underwood (ANL)
- 13:30 - 14:00
- "PRISM: Profiling-Free Symbolic Memory-Driven Strategy Planner for Large DNN Model Training"
- Ruiwen Wang, Philippe Fang, Chong Li, Thibaut Tachon, Raja Appuswamy
- 14:00 - 14:30
- "Exploring User Heterogeneity-Aware Differentiated Token Pricing for On-Premises Large Language Models"
- Lei Peng, Yujie He, Shuai Lv, Zhongxin Wu, Yang Yu, Yanlei Shi, Jianxing Zhai, Jiajie Sheng, Xingze Wang, Jianwen Wei
- 14:30 - 15:00
- "Optimizing Intra-Layer Parallel Communication for LLM Training on Systems with Fully-Connected Mesh GPU Topology"
- Ryubu Hosoki, Kento Sato, Toshio Endo, Julien Bigot, Edouard Audit
Wed, January 28, 2026 13:30 - 16:30 Room 701
Contributors: Aditi Subramanya, Jana Makar, Selphie Siew
Abstract: As we approach a future shaped by High-Performance Computing (HPC), Artificial Intelligence (AI), Cloud technologies, and Quantum Computing (QC), the call for a diverse, equitable, and inclusive (DEI) ecosystem has never been more urgent. The Diversity & Inclusivity Track at SC Asia 2026 will explore how today’s decisions in creating inclusive research, technical, and organisational environments will directly influence the innovation, ethics, and societal impacts of tomorrow.
This track invites speakers to reflect on the future society we are building and to examine how diverse perspectives can accelerate scientific discovery, create more robust and trustworthy AI systems, ensure equitable access to computational resources, and prepare the next generation of talent. Conversely, it challenges participants to consider the risks of inaction — from algorithmic bias to workforce homogeneity — and the societal costs of excluding underrepresented voices from shaping the digital future.
Through thought-provoking keynotes, case studies, and panel discussions, this track will bring together researchers, industry leaders, and policymakers to reimagine what inclusive excellence means in the era of HPC-driven transformation. Together, we will explore practical strategies to embed DEI principles into research collaborations, infrastructure design, governance frameworks, and talent pipelines, ensuring that future societies are not only technologically advanced but also just, equitable, and resilient.
Program:
- 13:30-13:35
- Track welcome
- Ms Aditi Subramanya (Pawsey Supercomputing Research Centre)
- 13:35-14:05
- Empowering Europe’s HPC Community Through Skills and Inclusion
- Ms Karina Pešatová (IT4Innovations National Supercomputing Center; and co-founder of the Central European Chapter of Women in HPC, Czechia (Czech Republic))
- 14:05-14:30
- A human-friendly hiring process
- Dr Pascal Jahan Elahi (Pawsey Supercomputing Research Centre)
- 14:30-15:00
- The Human Architecture of Computational Innovation
- Dr Freda Lim (Division Director, Institute of High Performance Computing (IHPC), A*STAR, Singapore)
- 15:00-15:30
- Break
- 15:30-16:00
- Gender bias in LLMs and human-AI collaborative workflows for low-resource languages
- Joy Yang (Principal Engineer and Director of Sales and Marketing Department, National Center for High-Performance Computing, National Institutes of Applied Research)
- 16:00-16:30
- Parallel Paths : Diversity and Inclusivity in HPC Through People, Fields, and Languages
- Julie Faure-Lacroix (Calcul Quebec, Canada)
- 16:30
- Thanks and close
- Aditi Subramanya (Pawsey Supercomputing Research Centre)
Wed, January 28, 2026 13:30 - 17:00 Room 801
Contributors: Kento Sato, Toshihiko Kai
Abstract: The rise of AI-driven scientific discovery is transforming the design and operation of high-performance computing (HPC) storage infrastructures. Modern research workflows increasingly combine large-scale simulation, experimental data acquisition, and machine learning, producing unprecedented demands for throughput, scalability, resilience, and intelligent data management. This half-day, multi-vendor panel session brings together leading storage technology providers to share their visions for next-generation storage architectures that can power both traditional HPC and emerging AI/ML workloads. Each speaker will deliver a technical and strategic presentation covering topics such as high-throughput parallel file systems, large-scale object storage, hybrid and tiered designs, and cloud-integrated solutions. These talks will address challenges including extreme data growth, optimizing I/O for AI training and inference, sustaining performance at scale, and balancing cost, energy efficiency, and sustainability. The session will conclude with a moderated panel discussion, where all speakers and the audience engage in a lively dialogue on technology trends, design trade-offs, real-world deployment lessons, and future directions in storage for AI-driven science. Attendees will gain vendor-neutral, strategic insights into the evolving storage landscape and leave with actionable ideas for architecting the next generation of HPC/AI data infrastructures.
Program:
- 13:30-13:40
- Opening
- 13:40-13:50
- "DAOS and AI-for-Science at Exascale"
- Michael Hennecke (Distinguished Technologist - HPC Storage, HPE)
- 13:50-14:00
- "IBM Data Engine for HPC and AI"
- Frank Lee (Director & Distinguished Engineer, IBM Storage WW Tech Sales Leader, IBM)
- 14:00-14:10
- "pNFS storage for large-scale HPC and AI"
- Yifeng Jiang (Principal Solutions Architect, Data Science, PURE STORAGE)
- 14:10-14:20
- "Architecture, Benchmarks, and Lessons from Leadership-Class Deployments"
- Kyle Eric Lamb (Field CTO for HPC, VAST)
- 14:20-14:30
- "New storage architecture in the age of data and intelligence"
- Spencer Sells (Vice President, Global Alliance, NetApp)
- 14:30-14:40
- "Modern AI infrastructure and how to break the Inference memory wall"
- Shimon Ben David (CTO, WEKA)
- 14:40-14:50
- "Velocity meets Durability"
- Samantha Mimoto (Samantha Clarke) (VP, Strategic Partnerships, VDURA)
- 14:50-15:00
- "Today and Tomorrow: Insights from Data Infrastructure (tentative)"
- Robert Triendl (SVP Sales, International DataDirect Networks, Inc.)
- 15:00-15:30
- Break
- 15:30-15:35
- Panel Discussion Opening (The chair poses a same question to all speakers)
- 15:35-15:45
- HPE (answer and discussion)
- 15:45-15:55
- IBM (answer and discussion)
- 15:55-16:05
- PURE STORAGE (answer and discussion)
- 16:05-16:15
- VAST (answer and discussion)
- 16:15-16:25
- NetApp (answer and discussion)
- 16:25-16:35
- WEKA (answer and discussion)
- 16:35-16:45
- VDURA (answer and discussion)
- 16:45-16:55
- DDN (answer and discussion)
- 16:55-17:00
- Closing
Wed, January 28, 2026 13:30 - 17:00 Room 702
Contributors: Qingchun Song, Pengzhi Zhu
Abstract: Data centers are rapidly transforming into AI factories, powered by tens of thousands of GPUs and accelerators. These environments run massive jobs across distributed clusters, making network performance critical to achieving the lowest latency and highest efficiency for both AI training and inference. In this new architecture, the network defines the AI Factory. RDMA technologies have become the backbone of scale-out computing, enabling high-performance east-west communication across GPUs and efficient north-south storage access. Optimizing RDMA communications is essential for boosting both compute and storage performance in large-scale AI and HPC clusters. The HPC-AI Advisory Council is dedicated to advancing these optimizations through cutting-edge technologies, training programs, and competitions.
Webstie: https://www.hpcadvisorycouncil.com/events/2025/APAC-AI-HPC/
Program:
- 13:30-13:40
- Opening
- 13:40-14:10
- Keynote: Scaling AI Factories with RDMA-Accelerated Fabrics
- Gilad Shainer (HPC-AI Advisory Council)
(bio)

Gilad Shainer serves as senior vice president of networking at NVIDIA. Gilad joined Mellanox in 2001 as a design engineer and has served in senior marketing management roles since 2005. He serves as the chairman of the HPC-AI Advisory Council organization, the president of the UCF and CCIX consortiums, a member of IBTA and a contributor to the PCISIG PCI-X and PCIe specifications. Gilad holds multiple patents in the field of high-speed networking. He is a recipient of the 2015 R&D100 award for his contribution to the CORE-Direct In-Network Computing technology and the 2019 R&D100 award for his contribution to the Unified Communication X (UCX) technology. Gilad holds a Master of Science and Bachelor of Science in electrical engineering from the Technion Institute of Technology in Israel.
- Abstract:
Data centers are evolving into full-scale AI factories, powered by tens of thousands of GPUs and accelerators operating as a single, distributed compute engine. In these massive environments, network performance is no longer a supporting component and has become the defining architecture of the AI Factory. Achieving ultra-low latency, high throughput, and predictable performance at scale is critical to maximizing the efficiency of both AI training and inference workflows.
Remote Direct Memory Access (RDMA) has emerged as the backbone of this architecture. RDMA enables high-performance east-west communication between GPUs, minimizes CPU overhead, and delivers the deterministic transport required for tightly coupled AI and HPC computations. At the same time, RDMA protocols power efficient north-south data access to storage systems, ensuring that expanding model sizes and dataset volumes do not become bottlenecks.
This session will explore the central role of RDMA in modern AI Factory design, examining how RDMA-accelerated fabrics (InfiniBand and Ethernet RoCE) unlock scalable performance across compute and storage layers. We will highlight real-world optimization strategies, emerging research, and lessons learned from global HPC-AI deployments. The HPC-AI Advisory Council continues to advance these capabilities through deep technical programs, hands-on training, and international competitions designed to prepare the next generation of engineers to build the world’s largest AI systems. - 14:10-14:30
- State-of-the-Art Communication Software for Supercomputers and Its Applications
- Jeff R. Hammond (NVIDIA)
(bio)

Jeff Hammond is a Principal Engineer at NVIDIA where he works on HPC software for GPUs and ARM CPUs. His research interests include parallel programming models and system architecture. Previously, Jeff worked at Intel and the Argonne Leadership Computing Facility where he worked on a range of projects, including MPI-3, oneAPI, Blue Gene and Xeon Phi. Jeff received his PhD in Chemistry from the University of Chicago for work on NWChem.
- Abstract:
I will talk about high-performance communication software for GPU supercomputers. I will explain NCCL and NVSHMEM, including their historical context from MPI and SHMEM. The functionality and performance will be demonstrated through an example from linear algebra. Real world results from both scientific and commercial AI use cases will be described. - 14:30-14:50
- Designing High-Performance and Scalable Middleware for the Modern HPC and AI Era
- Dhabaleswar K. (DK) Panda (The Ohio State University)
(bio)

DK Panda is a Professor and University Distinguished Scholar of Computer Science and Engineering at the Ohio State University. He is serving as the Director of the ICICLE NSF-AI Institute (https://icicle.ai). He has published over 500 papers. The MVAPICH MPI libraries, designed and developed by his research group (https://mvapich.cse.ohio-state.edu), are currently being used by more than 3,475 organizations worldwide (in 93 countries). More than 1.98 million downloads of this software have taken place from the project's site. This software is empowering many clusters in the TOP500 list. High-performance and scalable solutions for Deep Learning frameworks and Machine Learning applications from his group are available from https://hidl.cse.ohio-state.edu. Similarly, scalable, and high-performance solutions for Big Data and Data science frameworks are available from https://hibd.cse.ohio-state.edu. Prof. Panda is a Fellow of ACM and IEEE. He is a recipient of the 2022 IEEE Charles Babbage Award and the 2024 IEEE TCPP Outstanding Service and Contributions Award. More details about Prof. Panda are available at https://www.cse.ohio-state.edu/~panda.
- Abstract:
This talk focuses on challenges and opportunities in designing middleware for HPC and AI (Deep/Machine Learning) workloads on modern high-end computing systems. The talk initially presents the challenges in co-designing HPC software by considering support for dense multi-core CPUs, high-performance interconnects, GPUs, and DPUs. Advanced designs and solutions (such as RDMA, in-network computing, GPUDirect RDMA, on-the-fly compression) to exploit novel features of these emerging technologies and their benefits in the context of MVAPICH libraries (https://mvapich.cse.ohio-state.edu) are presented. Next, the talk focuses on MPI-driven solutions for the AI (Deep/Machine Learning) domains to extract performance and scalability for popular Deep Learning frameworks, large out-of-core models, and GPUs. The talk concludes with an overview of the activities in the NSF-AI Institute ICICLE (https://icicle.osu.edu/) to address challenges in designing future high-performance edge-to-HPC/cloud software for AI-driven data-intensive applications over the computing continuum. - 14:50-15:00
- 2025 APAC HPC-AI Competition Award Ceremony
- 15:00-15:30
- Break
- 15:30-15:40
- HPC Software Development - Challenges in Portability
- Chung Shin Yee (NSCC Singapore)
(bio)

Shin Yee is a Senior Assistant Director at the National Supercomputing Centre (NSCC) Singapore.
Shin Yee received his Bachelor of Engineering degree in Computer Engineering from Nanyang Technological University. He has more than a decade of experience working on custom software development, HPC software parallelisation and optimisation. The fields of development include graphics rendering, tomography data processing, vortex detection, and biometric recognition system.
Shin Yee leads the Frontier Team in NSCC building up the HPC capability in Singapore community, and enabling researchers to leverage the power of HPC systems for their scientific discovery effectively and efficiently. The team also builds and optimises HPC applications, runs HPC benchmarks to evaluate system & application performance, and establish best practices for HPC software.
- Abstract:
With new CPU and GPU being introduced every one to two years, HPC software development is facing tremendous challenges to catch up and optimise for the latest architectures. A piece of software usually stays in use for a much longer period than the lifetime of a HPC system. Heterogeneous hardware architectures post additional challenges to software development, how do we develop software for the architectures and achieve reasonably good performance at the same time? In this talk, we will walk through the current landscape of parallel programming and focus on the portability of HPC applications. We will also share our experience and view of HPC software development, helping the audience to navigate through the challenges to the future. - 15:40-15:50
- Training and Education initiatives at the National Computational Infrastructure, Australia
- Abdullah Shaikh (NCI Australia)
(bio)

Dr Abdullah Shaikh is a computational enthusiast who leads the skills development program at NCI Australia. He holds a PhD in environmental sustainability, specialising in applying machine learning and data science to ecological challenges. As a seasoned expert in skills development training, Dr. Shaikh is passionate about leveraging High-Performance Computing, Artificial Intelligence, and Data Science to tackle complex research problems.
- Abstract:
NCI is one of the two national HPC facilities in Australia, providing exceptional HPC and Data services to Australian researchers. The presentation by Dr Shaikh will highlight the computational capabilities of NCI facilities and services, including our skills development activities and initiatives to boost HPC talent. - 15:50-16:00
- Presentation from Firmus
- Swe Aung (Firmus)
(bio)

Swe Aung is a technologist specializing in High-Performance Computing, distributed AI systems, and cloud computing infrastructure, with over 18 years of experience architecting and delivering large-scale computational platforms.
He leads Software Deigned Infrastructure, Cloud & HPC at Firmus Technologies, driving innovations in software-defined architecture and overseeing the commissioning and delivery of large-scale, fit-for-purpose AI infrastructures.
Prior to Firmus Technologies, Swe played key role at a sovereign cloud for Australia’s critical infrastructure and led the development and operation of Australia’s National Research Cloud (ARDC) at Monash University. He has contributed to major national and industrial research computing initiatives and advanced HPC designs, with his work presented at the OpenInfra Summit, eResearch Australasia and the HPC-AI Advisory Council.
- 16:00-16:10
- Overview of RIKEN R-CCS: Home of the Supercomputer Fugaku
- Kengo Nakajima (The University of Tokyo / RIKEN R-CCS)
(bio)

Kengo Nakajima has been a professor in the Supercomputing Research Division of the Information Technology Center at the University of Tokyo since 2008. Prior to joining the University of Tokyo in 2004, he spent 19 years in industry. Kengo has also been a deputy director of RIKEN Center for Computational Science (R-CCS) since 2018. His research interests cover computational mechanics, computational fluid dynamics (CFD), numerical linear algebra, parallel iterative algorithms, parallel preconditioning methods, multigrid methods, parallel programming models, adaptive mesh refinement (AMR), and parallel visualization. Kengo holds a B.Eng in aeronautics (University of Tokyo, 1985), an MS in aerospace engineering (University of Texas at Austin, 1993), and a PhD in engineering mechanics (University of Tokyo, 2003).
- Abstract:
RIKEN R‑CCS is Japan’s national supercomputing hub. Its mission is threefold: the Science of Computing—advancing high‑performance computation as a discipline; the Science by Computing—applying massive compute to solve difficult scientific problems; and the Science for Computing—collaborating across fields to drive advances that benefit both. R‑CCS integrates simulation, data science, and AI to build digital twins and extract insight from models and measurements, with supercomputers amplifying every method. The center develops pioneering technologies that shape the future of IT. Key initiatives include AI for Science—accelerating research with foundation models under RIKEN’s Advanced General Intelligence for Science Program (AGIS); the JHPC‑Quantum Platform—coupling quantum resources with supercomputers to tackle previously intractable workloads; and FugakuNEXT—a next‑generation flagship combining simulation and AI to sustain global leadership. This talk quickly overviews these activities. - 16:10-16:20
- From Wasted Cycles to Wise Systems: Coaching the Next Generation of Ethical AI-Accelerated HPC
- Worawan Diaz Carballo (Thammasat University)
(bio)
Dr. Worawan Diaz Carballo (Marurngsith) is an Assistant Professor of Computer Science at Thammasat University, Thailand, and principal investigator of the HPC Ignite Initiative, a capacity-building program supported by Thailand's NRCT and ThaiSC. Her research focuses on HPC systems, AI workload efficiency, and hybrid HPC/AI/cloud integration for education and innovation.
Through HPC Ignite, she has trained over 370 learners in Northern Thailand, developing projects that address societal challenges using supercomputing and AI. She has supervised award-winning teams from Thammasat University for eight years, ensuring Thailand's contribution to Asia-Pacific HPC and AI competitions. An alumnus of seven ACM HPC Seasonal Schools and teaching assistant for three, she was recently featured in ACM's "People of ACM" series for her work expanding computational education in underserved regions.
Dr. Diaz Carballo serves as the faculty sponsor of the ACM SIGHPC Student Chapter at Thammasat University, advancing HPC innovation from the local to the international scale.
- Abstract:
Drawing on emerging community efforts around trustworthy compute, broadening participation as evidenced by the growing number of competition teams, and accessible HPC-AI education, a new challenge arose: "How do we ensure novices really learn by having ethically responsible AI companions?" In both competition training and onboarding 373 novice users in a capacity-building project in Thailand, the year 2025 saw a sharp corner in which novice users accepted AI-generated recommendations across multiple stages of their workflow without adequate verification—posing clear risks when transplanted into HPC environments. A more intelligent model with greater capabilities, commercial or open-weight, was arriving at least monthly; however, we need at least six months to train novices. These experiences highlight an emerging divide between increasingly "smart" systems and the "wise" practices required to use them safely and equitably.
This talk reflects on those experiences and makes a broader call to action for the community to move beyond technical metrics to address the ethical and pedagogical imperatives of the AI era. The role of the modern HPC coach must shift from teaching pure performance to teaching "system wisdom"—the ability to audit, verify, and ethically manage AI outputs. We cannot avoid wasting cycles to train novices. However, in the rapidly accelerating AI era, our shared responsibility is to develop HPC talent that builds systems that help us transform wasted cycles into wiser systems—and wiser users. - 16:20-16:30
- Lessons Learned from the HPC competitions
- JIA-HONG LIN (National Tsing Hua University)
(bio)

JIA-HONG LIN is a junior student majoring in computer science at National Tsing Hua University in Taiwan. He is passionate about learning across the broad spectrum of computer science—from frontend and backend development to mobile apps and machine learning. He started to participate in the HPC competitions after joining the NTHU team organized by Prof. Chou in 2025, and he is the team leader of the HPC-AI competition team “Yi Da Tuo”.
- Abstract:
After participating in three mock contests and two official HPC competitions, I would like to share the confusion and uncertainty I often experienced as a team member while solving the problems. I spent countless hours tuning, debugging, and learning new tools—but would these skills really matter in the future? In this talk, I will reflect on that sense of doubt and also on the things I learned from the competitions—not only technical improvements, but also growth in mindset, collaboration, and the ability to work through the unknown. - 16:30-16:40
- An Optimization Workflow for Scientific Computing and AI Workloads in APAC HPC-AI
- Haibin Lai (Southern University of Science and Technology)
(bio)

Haibin Lai is a senior Computer Science undergraduate at Southern University of Science and Technology (SUSTech), focusing on high-performance computing and AI systems. His work spans CPU/GPU optimization, distributed AI inference, and runtime design. He has experience in tuning scientific and AI workloads on large-scale clusters, leading his team to Second place and the Excellent AI Performance Award at APAC HPC-AI 2025 and Third place at APAC HPC-AI 2024.
- Abstract:
Optimizing both scientific computing applications and AI workloads requires a structured and generalizable methodology. In this talk, I will introduce the unified workflow our team used during the APAC HPC-AI Competition to achieve efficient and repeatable performance improvements across heterogeneous tasks. Our approach consists of three key stages: systematic profiling, bottleneck identification, and targeted optimization. For scientific computing software, we focus on algorithm hotspots, parallel efficiency, and MPI communication. For AI workloads, we emphasize GPU utilization, kernel-level analysis, and communication utilization. I will also discuss how we organized our team with clear module ownership to enable rapid iteration. This high-level workflow allowed us to deliver competitive performance consistently across diverse HPC-AI challenges. - 16:40-16:50
- 2026 APAC HPC-AI Competition Announcement
- 16:50-17:00
- Closing
Wed, January 28, 2026 13:30 - 17:00 Room 1101
Contributors: Toshiyuki Imamura (RIKEN R-CCS)
Abstract: Recent advances in AI-empowered CPUs, NPUs, and GPUs significantly improve low- and mixed-precision calculations. This invited session will explore cutting-edge theory regarding mixed-precision techniques and their applications, including key algorithms, AI device design, and circuit implementation, focusing on how they can speed up non-AI tasks. The main goal of the session is to provide a detailed review of the Ozaki-scheme, which emulates FP64-GEMM operations using low-precision INT8 GEMMs, and to evaluate its performance and potential, especially in existing systems and the FugakuNEXT generation. Additionally, the session will showcase other innovative methods enhanced by sophisticated MxP algorithms utilizing advanced numerical linear algebra and application co-design.
Program:
- 13:30-13:35
- Opening
- 13:35-14:15
- Plenary talk: Ozaki Schemes I and II: Emulated Matrix Multiplication and Its Applications
- Prof. Ozaki (Shibaura Inst.Tech)
- Abstract:
In this talk, I will introduce Ozaki Schemes I and II, which are known as emulated matrix-multiplication methods. I will discuss not only the difference in computational speed between the two schemes, but also other essential distinctions. Applications to numerical linear algebra will also be presented.
- 14:15-15:05
- 1st session the AI devices, programming environments, algorithms, enabling MxP
- 1. Mixed-Precision Algorithms and Tools for AI Era GPUs
- Harun Bayraktar (NVIDIA)
- Abstract:
In this talk, we will provide a structured overview of the floating point and block scaled formats available in contemporary GPU architectures and discuss how their properties reshape algorithm design. We argue that mixed precision is not merely a performance optimization, but a paradigm shift that requires rethinking numerical methods to achieve higher performance and better energy efficiency while still preserving accuracy. To illustrate the inherent opportunities and challenges, we use a mixed-precision symmetric eigenvalue solver. Finally, we address a central barrier to progress: easy experimentation with various precisions. We will preview a new experimental analysis tool that aims to make mixed-precision experiments more systematic, helping developers be more productive in exploring precision spaces, estimating sensitivities, and designing algorithms that are both fast and numerically reliable.
- 2. Mixed-precision Computation on the MN-Core Architecture
- Kentaro Nomura (Preferred Network)
- Abstract:
This presentation provides an overview of the MN-Core architecture, an AI accelerator, as well as its supported floating-point number formats. We further describe the associated HPC development environments, MNCL and MNACC, which facilitate efficient application development and optimization on this platform. Using the interaction kernel of a molecular dynamics simulation as an example, we demonstrate an implementation of mixed-precision computation for MN-Core 2. - 15:05-15:30
- Break
- 15:30-16:45
- 2nd session for Numerical algorithm and applications of Ozaki-scheme
- 3. Adaptive Mixed-Precision Algorithms for Next-Generation Scientific Simulations
- Hatem Ltaief (KAUST)
- Abstract:
The future of large-scale simulations is increasingly tied to hardware features originally designed for AI workloads—especially low-precision arithmetic. Modern GPUs embody this shift, delivering substantial speedups through reduced-precision computations that lower execution time, shrink memory footprints, and cut energy consumption. Building on these capabilities, we design fast mixed-precision linear algebra algorithms that adaptively choose the right precision at the right moment. Our dynamic precision-conversion strategy preserves high accuracy only where it truly matters, all while maintaining application-level numerical reliability. This talk will demonstrate how these algorithms reshape computational efficiency for geospatial statisticians and geophysicists, with far-reaching benefits for environmental computational statistics, seismic imaging, and beyond.
- 4. A Nested Krylov Strategy for Efficient Sparse Linear Solvers Using FP16 Arithmetic
- Kengo Suzuki (Kyoto University)
- Abstract:
In this talk, I will present a mixed-precision approach for developing efficient sparse iterative linear solvers that leverage half-precision floating-point (FP16) arithmetic. Our strategy uses a nested structure of multiple Krylov solvers to fully exploit FP16 computations. I will also introduce a concrete solver constructed using this strategy and show numerical results demonstrating its advantages over widely used Krylov solvers such as CG and GMRES.
- 5. Impact of MxP on Numerical Libraries
- Toshiyuki Imamura (RIKEN)
- Abstract:
The MxP discussed in this session covers various approaches that combine different levels of computational precision as needed to simulate both low- and high-precision calculations. The main idea is to actively manage the computational workload to achieve the desired arithmetic precision by selecting appropriate computational accuracy and handling complex optimization tasks, thereby reducing overall computational costs. In the final presentation, we used the Ozaki method on a GPU-based dense-matrix numerical computation library, creating a clear cost model for balancing computational accuracy and time. We also provide an engineering example of next-generation optimization of numerical libraries using MxP to demonstrate the method's effectiveness. - 16:45-16:55
- Discussions
- 16:55-17:00
- Closing
Wed, January 28, 2026 13:30 - 17:00 Room 1009
Contributors: Mitsuhisa Sato, Ye Jun
Abstract: Quantum computing is a promising technology that extends the frontiers of computation beyond existing high-performance computers. Although current state-of-the-art supercomputers have solved many scientific problems, quantum computers are expected to further explore their computational capabilities as the most powerful accelerators. Before reaching “quantum advantage,” “quantum utility” has emerged as a new measure of practical usefulness in the field of quantum computing. At present, extensive research and development on systems and applications toward achieving quantum utility—and ultimately quantum advantage—is actively progressing across the Asia-Pacific region. This session highlights the cutting edge of quantum computing: the first part introduces key initiatives in the Asia-Pacific region, while the second part focuses on systems and applications.
Program:
- 13:30-13:35
- Opening
- 13:35-14:05
- Open Quantum-GPU Supercomputing: Building the Fault-Tolerant Future Together
- Sam Stanwyck (NVIDIA)
- 14:05-14:35
- Creating Value from HPC-QC: A Perspective from the Chemical Industry
- Yu-ya Ohnishi (JSR Corporation)
- 14:35-15:05
- Training Hybrid Deep Quantum Neural Network for Efficient Reinforcement Learning
- Georgios Korpas (HSBC and Czech Technical University)
- 15:05-15:20
- Break
- 15:20-15:50
- Towards practical applications of quantum chemistry via quantum-HPC hybrid computing
- Seiji Yunoki (RIKEN)
- 15:50-16:20
- Building a Quantum-Ready Ecosystem: Singapore’s Approach
- Su Yi (A*STAR IHPC)
- 16:20-16:50
- Pawsey Quantum Supercomputing Innovation Hub and Hybrid Computing
- Pascal Jahan Elahi (Pawsey Supercomputing Research Centre)
Wed, January 28, 2026 13:30 - 17:00 Room 802
Contributors: Akihiro Asahara
Abstract: This invited session explores the latest advances in performance engineering for HPC systems running AI workloads, bridging operational practices and architectural innovation.
We will discuss continuous telemetry-based performance observation, identification of typical bottlenecks in AI training and inference pipelines, and practical models for iterative optimization across software, middleware, and system layers. Real-world case studies will demonstrate how systematic performance engineering achieves significant efficiency gains in large-scale GPU clusters. The session also looks ahead to how evolving AI models, heterogeneous accelerators, and exascale architectures are reshaping HPC operations and performance management frameworks.
Speakers from academia and industry will share both theoretical and practical insights, highlighting opportunities for collaboration and cross-sector innovation toward sustainable, high-efficiency computing in the AI era.
Program:
- 13:30-13:35
- Opening Remarks
- 13:35-14:00
- "Beyond the Abstraction Layer: When AI Optimizes AI"
- Takuro Iizuka (CTO at Fixstars)
- 14:00-14:25
- "The mdx Ecosystem: From Academic Cloud Infrastructure to AI Inference and Modeling"
- Toyotaro Suzumura (Professor at the University of Tokyo)
- 14:25-14:50
- "Running AI Inference at Scale on AI-Ready Infrastructure at GMI Cloud"
- Andy Chen (VP of Global Business and Product Development at GMI Cloud)
- 14:50-15:10
- Break
- 15:10-15:35
- "An Operational Retrospective on Cloud-Native AI Supercomputers with Kubernetes"
- Tatsuhiro Chiba (Senior Technical Staff Member at IBM Research)
- 15:35-16:00
- "Current Methodologies in Practical Performance Engineering for AI Workloads and Future Perspectives with Open Architectures"
- Naoki Yoshifuji (Field Application Engineer, Tenstorrent Inc.)
- 16:00-16:25
- "AI in scientific computing – the hybrid journey"
- Thierry Pellegrino, Global Head of Advanced Computing at Amazon Web Services
- 16:25-17:00
- Panel discussion: Towards Continuous Performance Engineering for AI-HPC Integration
- All Speakers, moderated by Aki Asahara, CMO at Fixstars
Wed, January 28, 2026 13:30 - 17:00 Room 1007
Contributors: Jin-Sung Kim
Abstract: Quantum computing has the potential to solve the world’s most important problems, however useful quantum computers will not exist in a silo. The global HPC community recognizes that the first useful quantum applications will be hybrid, requiring a deep and performant integration between quantum processors and classical HPC & AI supercomputers. This session convenes thought leaders from across these domains to address a pressing challenge that will define the next era of supercomputing: the integration of quantum computers with AI supercomputers.
Experts within the industry agree that quantum computers working in tandem with classical HPC and AI supercomputing will be key to unlocking useful applications within quantum computing. The reasons are twofold:
- While quantum computers are expected to accelerate specific algorithms that are classically intractable, the majority of an industrially useful application will still be a classically optimized workflow intended to run on an HPC cluster.
- The most rigorous instances of known quantum advantage rely on implementing quantum error correction (QEC), whereby many physical qubits encode single logical qubits. To execute error correction, measurements of error syndromes from the quantum processor must be taken at high frequency and passed to a classical processor with low latency to compute and correct the corresponding error. This process of error correction decoding is known to be computationally intensive and can benefit from the scalability from today’s HPC and AI compute fabric.
A performant, scalable, and low-latency interface between AI supercomputers and quantum computers is the key technical innovation required. The interface should be common and easily adaptable by quantum processor unit (QPU) builders and QPU system controller (QSC) builders and should integrate readily with HPC resources. Software architectures should provide support for real-time callbacks and data marshaling between the HPC and QSC to provide support for QEC decoding and hybrid quantum-classical applications. This session will spark a forward-looking discussion on existing and future architectures, software, and standards needed to implement this "quantum-classical" compute fabric.
Program:
- 13:30-14:00
- Talk 1: System design for FPGA-based quantum error correction experiments with superconducting qubits
- Kentaro Sano (RIKEN)
Bio: Kentaro Sano is the principal of the processor research team, and the leaders of the advanced AI device development unit and the next-generation high-performance computing infrastructure system development unit at RIKEN Center for Computational Science (R-CCS), responsible for research and development of future processors and systems for HPC and AI. He is also a visiting professor with an advanced computing system laboratory at Tohoku University. He received his Ph.D. from the graduate school of information sciences, Tohoku University, in 2000. Since 2000 until 2018, he was a Research Associate and an Associate Professor at Tohoku University. He was a visiting researcher at the Department of Computing, Imperial College, London, and Maxeler Technology corporation in 2006 and 2007. His research interests include data-driven and spatial-parallel processor architectures such as a coarse-grain reconfigurable array (CGRA) for HPC and AI, FPGA-based high-performance reconfigurable computing, quantum error correction hardware for fault-tolerant quantum computers, and system architectures for next-generation supercomputers including FugakuNEXT. - 14:00-14:30
- Talk 2: NVQLink: Accelerated computing for the QPU
- Shane Caldwell (NVIDIA)
Bio: Shane Caldwell is the product manager for NVIDIA NVQLink. He works with partners across the quantum computing industry to accelerate every QPU and help them successfully integrate with the supercomputing environment. He has a PhD in experimental physics and a background in building QPUs with superconducting qubits at Rigetti Computing. - 14:30-15:00
- Talk 3: Hybrid control unlocking quantum supercomputers
- Wei Dai (Quantum Machines)
Bio: Wei Dai is a Product Solutions Physicist at Quantum Machines, leading product research to advance quantum control technologies. Wei earned a Ph.D. in Applied Physics from Yale University, with his research focused on superconducting qubits. - 15:00-15:30
- Break
- 15:30-16:00
- Talk 4: Real-time decoding with GPU: a case study of tightly coupled classical co-processor with QPU
- Alex Chernoguzov (Quantinuum)
Bio: Alex is a Quantinuum Fellow and a software architect responsible for all levels of quantum computer software stack from control system directly manipulating qubits to cloud software providing end users remote access to quantum processors. Alex's professional career starts at Honeywell in 1995. Prior to transitioning to Quantinuum predecessor, Honeywell Quantum Solutions, he was involved in developing industrial control systems, wireless sensor networks, automotive software, and cyber security research leading to many successful commercial products. Alex received his undergraduate degree in Physics from Moscow Institute of Physics and Technology and MSEE degree from University of Delaware. - 16:00-17:00
- Panel Discussion
Wed, January 28, 2026 15:30 - 17:00 Room 1002
Chair: Alexandre Bardakoff (RIKEN)
- 15:30 - 16:00
- "A Multi-ROI Camera Motion Exploration Approach for Enhancing Image-based Smart In-Situ Visualization"
- Taisei Matsushima, Kazuya Adachi, Naohisa Sakamoto, Jorji Nonaka
- 16:00 - 16:30
- "ROIX-Comp: Optimizing X-ray Computed Tomography Imaging Strategy for Data Reduction and Reconstruction"
- Amarjit Singh, Kento Sato, Kohei Yoshida, Kentaro Uesugi, Yasumasa Joti, Takaki Hatsui, Andrès Rubio Proaño
- 16:30 - 17:00
- "Scalable eVTOL Aerodynamics Simulations on Heterogeneous HPC Platforms with Minimal-Invasive GPU Porting"
- Peter Ohm, Ayato Takii, Kazuto Ando, Rahul Bale, Makoto Tsubokura
Wed, January 28, 2026 15:30 - 17:00 Room 1008
Chair: Bogdan Nicolae (ANL)
- 15:30 - 16:00
- "Fusing Sequence Motifs and Pan-Genomic Features: Antimicrobial Resistance Prediction using an Explainable Lightweight 1D CNN - XGBoost Ensemble"
- Md. Saiful Bari Siddiqui, Nowshin Tarannum
- 16:00 - 16:30
- "High-performance in-situ ML Inference with dalotia: A Lightweight Tensor Loader API for Science Codes"
- Theresa Pollinger, Jens Domke
Wed, January 28, 2026 17:00 - 18:00 Room 701
Contributors: Troy Patterson, Frank Herold
Wed, January 28, 2026 17:00 - 18:00 Room 801
Contributors: Takaaki Miyajima
Website: https://sites.google.com/view/wsc-bof-sca-hpcasia2026
Wed, January 28, 2026 17:00 - 18:00 Room 802
Contributors: Pascal Jahan Elahi
Wed, January 28, 2026 17:00 - 18:00 Room 1002
Contributors: Johannes Gebert, Josef Weidendorfer
Wed, January 28, 2026 17:00 - 18:00 Room 1007
Contributors: Swann Perarnau, Brice Videau
Wed, January 28, 2026 17:00 - 18:00 Room 1008
Contributors: Todd Gamblin, Gregory Becker
Wed, January 28, 2026 17:00 - 18:00 Room 1009
Contributors: Karina Pesatova
Wed, January 28, 2026 17:00 - 18:00 Room 1001
Contributors: Gabriel Noaje, John Josephakis
Abstract: Join a panel of global HPC visionaries moderated by John Josephakis, Global VP of Sales and Business Development for HPC/Supercomputing at NVIDIA
Explore how breakthroughs in artificial intelligence, quantum computing, and next-generation infrastructure are shaping the boundaries of scientific research.
Gain insights from pioneers revolutionizing fields such as high-energy physics, drug discovery, astrophysics, and materials science. Discover how NVIDIA, together with our customers and partners, is redefining what’s possible at the intersection of supercomputing and science.
Don’t miss this chance to connect, ask questions, and be inspired alongside leaders who are catalyzing the next era in HPC.
Panelists:
- Prof. Satoshi Matsuoka (R-CCS), Director of RIKEN Center for Computational Science, Japan
- Prof. Rick Stevens (ANL), Associate Director for the Computing, Environment and Life Sciences (CELS) Directorate at Argonne National Laboratory’s Leadership Computing Facility (ALCF), United States of America
- Prof. Thomas Schulthess (CSCS), Director of the Swiss National Supercomputing Center, Switzerland
- Dr. Terence Hung (NSCC) – Chief Executive, National Supercomputing Centre Singapore, Singapore
- Mr. John Josephakis (NVIDIA) - Global VP, Sales and Business Development (HPC/Supercomputing), NVIDIA (Moderator)
Wed, January 28, 2026 17:00 - 18:00 Room 1102
Contributors: Soratouch Pornmaneerattanatri
Wed, January 28, 2026 17:00 - 18:00 Room 1202
Contributors: Filippo Spiga (NVIDIA), James Lin (SJTU)
Abstract:
Arm has taken over a decade to establish itself in the datacentre, and today its ecosystem is rapidly growing. With broad adoption by multiple providers and consumers, Arm is gaining increasing market share in high-performance computing. The increasing number of Arm-based installations, both in the East and West sides of the world, highlights the global momentum. Establishing deep collaborations, especially in software, presents unique opportunities to accelerate adoption and maturity. By working together under the principle that a “rising tide lifts all boats”, we can build a stronger and more cohesive Arm ecosystem for the benefit of society through computing. This BoF aims to bootstrap a conversation regarding the current status-of-the-union of the Arm software ecosystem from a collaborative perspective. It represents a moment for debate and reflection with the objectives to build bridges between the “East” and “West” sides of the world. The focus is cantered primarily on software and join research and development actions which can boost adoption and awareness.
Panelists:
- Christopher Woods, University of Bristol / BriCS (United Kingdom)
- Toshihiro Hanawa, University of Tokyo (Japan)
- Dan Stanzione, Texas Advanced Computing Centre (USA)
- Jian Guo, Xi’an University of Finance and Economics (China)
- Fabio Banchelli, Barcelona Supercomputing Centre
- Filippo Spiga, NVIDIA and Arm HPC User Group (United Kingdom) — Moderator
Tue, January 27, 2026 9:30 - 17:00
Wed, January 28, 2026 9:00 - 17:00
Thu, January 29, 2026 9:00 - 15:30
Venue: 3F Event Hall
Exhibitor List:
Nearly 100 exhibitors will showcase their latest technologies, products, and research results. Please see the exhibitor list and floor map below.
Exhibitor List and Floor Plan (PDF)
Exhibitors Forum:
During the exhibition hours, exhibitors will deliver 15-minute presentations. Please see the detailed program below.
Exhibitors Forum
Thu, January 29, 2026 09:00 - 09:45 5F Main Hall
Session Chair: Mohamed Wahib (RIKEN)

Speaker
- Katherine Yelick
- Robert S. Pepper Distinguished Professor of Electrical Engineering and Computer Sciences and Vice Chancellor for Research, UC Berkeley, USA
Senior Faculty Scientist, Lawrence Berkeley National Laboratory, USA
Biography
Katherine Yelick is the Vice Chancellor for Research at the University of California, Berkeley, where she also holds the Robert S. Pepper Distinguished Professor of Electrical Engineering and Computer Sciences. She is also a Senior Faculty Scientist at Lawrence Berkeley National Laboratory. She has been recognized for her research and leadership in high performance computing and is a member of the National Academy of Engineering and the American Academy of Arts and Sciences.
Abstract
The first generation of exascale computing systems are online along with powerful new application capabilities and system software. At the same time, demands for high performance computing continue to grow for more powerful simulations, adoption of machine learning methods, and huge data analysis problems arising for new instruments and increasingly ubiquitous data collection devices. In its broadest sense, computational science research is expanding beyond physical and life sciences into social sciences, public policy, and even the humanities.
With chip technology facing scaling limits and diminishing benefits of weak scaling, it will be increasingly difficult to meet these new demands. Disruptions in the computing marketplace, which include supply chain limitations, a shrinking set of system integrators, and the growing influence of cloud providers are changing underlying assumptions about how to acquire and deploy future supercomputers. At the same time AI is having an enormous influence on hardware designs, leaving traditional scientific methods at a crossroads – do the join the AI bandwagon or try to use the hardware for traditional methods?
In this talk I’ll present some of the findings of a US National Academies consensus report on the future of post-exascale computing, which states that business as usual will not be sufficient. I will also give my own perspectives on some of the challenges and opportunities faced by the research community.
Thu, January 29, 2026 09:45 - 10:30 5F Main Hall
Session Chair: Mitsuhisa Sato (Juntendo University/RIKEN)

Speaker
- Jay M. Gambetta
- Director of Research and IBM Fellow
IBM, USA
Biography
Dr. Jay M. Gambetta is the Vice President in charge of IBM’s overall Quantum initiative. He was named as an IBM Fellow in 2018 for his leadership in advancing superconducting quantum computing and establishing IBM’s quantum strategy to bring quantum computing to the world, and to make the world quantum safe.
Under his leadership, IBM was first to demonstrate a cloud-based quantum computing platform; a platform that has grown to become the predominant quantum service utilized by 600,000+ users to run over 3 trillion quantum circuits. These users include 280+ members of the IBM Quantum Network, representing forward-thinking academic, industry, and governmental organizations focused on building a quantum-native ecosystem. IBM Quantum continues to expand in the market by providing Quantum as a Service utilizing the IBM Quantum System One and Two series of devices, and to date has deployed over 75 quantum systems online, building the foundations of the quantum industry. In addition, he was responsible for the creation and early development of Qiskit; the leading open-source quantum computing software development kit, allowing users to build, optimize, and execute quantum circuits on hardware from a multitude of quantum service providers.
Dr. Gambetta received his Ph.D. in Physics from Griffith University in Australia. He is a Fellow of the American Physical Society, IEEE Fellow, and has over 130 publications in the field of quantum information science with over 50,000 citations.
Abstract
As quantum computing pushes into the era of advantage, algorithm development comes to the forefront as a crucial step from advantage to useful quantum computing. To facilitate this transition, the quantum industry needs a focus on performant hardware, performant software, and seamless integration between classical and quantum resources. In this talk, Jay will discuss IBM’s strategy for quantum computing, including advances in quantum-centric supercomputing software and algorithms, and IBM’s hardware roadmap leading to large-scale fault-tolerant quantum computers. Together, we are building the future of computing.
Thu, January 29, 2026 10:30 - 11:00 5F Main Hall
Thu, January 29, 2026 11:30 - 12:30 Room 1001
Contributors: Taisuke Boku, Colin McMurtie
Thu, January 29, 2026 11:30 - 12:30 Room 801
Contributors: Theresa Pollinger, Chia-Lee Yang
Thu, January 29, 2026 11:30 - 12:30 Room 802
Contributors: Keita Teranishi, Brian van Essen
Thu, January 29, 2026 11:30 - 12:30 Room 702
Contributors: Vikram Bahl
Thu, January 29, 2026 11:30 - 12:30 12F Conference Hall
Contributors: Christopher Schlipalius
Website: https://sites.google.com/view/data-storage-filesystems-bof/
Thu, January 29, 2026 11:30 - 12:30 Room 1202
Contributors: Amir Shehata, Mitsuhisa Sato
Thu, January 29, 2026 11:30 - 12:30 Room 1101
Contributors: Kazutomo Yoshii, John Shalf, Kentaro Sano
Thu, January 29, 2026 11:30 - 12:30 Room 1008
Contributors: Todd Gamblin, Christian Trott
Thu, January 29, 2026 11:30 - 12:30 Room 1009
Contributors: Gabriel Noaje
Abstract:
AI is revolutionizing healthcare by seamlessly integrating digital and physical technologies to address critical industry challenges. Digital AI agents now provide round-the-clock, individualized healthcare services, significantly reducing the administrative burden on medical teams. Concurrently, the convergence of AI and biology offers unprecedented insights into biological processes, enabling the exploration of vast therapeutic possibilities. In the physical realm, AI-powered medical devices and robotics enhance precision in diagnostics and treatments while optimizing operational efficiency. Domain-specific computing platforms are fostering a more responsive and patient-centric healthcare ecosystem. These advancements collectively promise to improve health outcomes on a global scale, marking a transformative chapter in medical history.
Pharma companies are developing their own supercomputing capabilities to advance medical discovery. Researchers in the medical domain are constantly building new tools to advance this domain like Alphafold who's authors won the Nobel prize recently.
As an emerging field the goal is to create a community of practitioners that can exchange ideas and best practices.
Don’t miss this chance to join this panel of experts, connect, ask questions, and be inspired alongside leaders who are catalyzing the advances in life sciences enabled by HPC and AI.
Panelists:
- Prof. Jun Sese - Professor at Tokyo Institute of Technology, and a Research Team Leader at the National Institute of Advanced Industrial Science and Technology (AIST)
- Prof. Giuseppe M. J. Barca - Professor of Quantum Medicinal Chemistry (MIPS) & High-Performance Computing (ANU), Co-Founder & Head of Research (QDX), Monash Institute of Pharmaceutical Sciences, ANU, QDX Technologies
- Dr. Luo Tao - Senior Scientist, Institute of High Performance Computing (IHPC), A*STAR Singapore
- Hidenoir (Tak) Yamada - Developer Relations Manager, Healthcare and Life Sciences, NVIDIA Japan
- Dr. Gabriel Noaje – HPC Business Development Lead Asia Pacific, NVIDIA (moderator)
Thu, January 29, 2026 11:30 - 17:00 Room 1003
Contributors: Rio Yokota, Jason Haga
Abstract: The 18th Accelerated Data Analytics and Computing (ADAC) Symposium is a co-located event at SCA/HPCAsia 2026, bringing a prestigious global HPC forum to Osaka, Japan. Scheduled for January 29, 2026, this open symposium will be part of the main conference program and is accessible to all HPC-Asia/SC-Asia participants. Under the theme “Beyond Classical Boundaries: HPC for Next Generation AI and Quantum Computing”, the ADAC18 Symposium explores how high-performance computing is transcending traditional limits to empower breakthroughs in artificial intelligence (AI) and quantum computing. The symposium will showcase cutting-edge research and collaborative initiatives at the intersection of supercomputing, AI, and quantum technologies, aligning with SCA/HPCAsia’s vision of uniting these communities to create the future. Attendees can expect insightful talks, networking opportunities, and a forward-looking dialogue on the future of computational science beyond classical HPC.
Website: https://adac.ornl.gov/18th-adac-symposium-workshop-january-29-february-2-4-2026/
Program:
- 11:30-11:35
- Welcome & Opening
- Jason Haga (AIST), Tjerk Straatsma (ORNL)
- 11:35-12:30
- Keynote Presentation
- Tadashi Kadowaki (AIST)
- 12:30-13:30
- Lunch Break
- 13:30-14:00
- Federation and Trusted Research Environment on UK AI Research Resources (AIRR)
- Sadaf Alam (UBristol)
- 14:00-14:30
- Presentation
- Weicheng Huang (NCHC)
- 14:30-15:00
- Presentation
- Dan Stanzione (TACC)
- 15:00-15:30
- Break
- 15:30-16:00
- The Future of High Performance Computing in Australia Hangs in the Balance
- Andrew Rohl, NCI
- 16:00-16:30
- HPC in the Little Red Dot
- Terence Hung (NSCC)
- 16:30-17:00
- Quantum as an accelerator for HPC: Current status and challenges
- Eric Mansfield (IQM)
- 17:00-17:30
- Navigating Uncertainty: Bridging Data, Models and HPC
- Antigoni Georgiadou (ORNL)
- 17:30-18:00
- The Evolution of GPU Programming (for HPC Applications)
- Mohammad Wahib (RIKEN)
Thu, January 29, 2026 11:30 - 18:30 Room 1002
Contributors: Jay Boisseau (Google Cloud), Doug Jacobsen (Google Cloud), Arvind Ramanathan (Argonne National Laboratory)
Abstract: The convergence of AI and HPC has achieved great success in optimizing infrastructure for AI model training and in using AI surrogates to approximate HPC simulations. There have been additional early successes in AI-assisted HPC code development and code optimization. However, the potential for AI to accelerate scientific discovery extends far beyond these distinct tasks. AI can augment scientists’ efforts throughout the entire computational scientific research pipeline. This full-day tutorial introduces a holistic paradigm: AI-Accelerated Computational Science, where AI tools are leveraged at every stage of the research lifecycle. From deep literature research and hypothesis generation, to research planning and code development, to code optimization and execution, to the final data interpretation and new insight, AI tools can augment expertise and enhance results in every step. A new generation of AI-powered tools and agentic systems leveraging powerful LLMs and other ML techniques is poised to greatly simplify and accelerate the entire scientific pipeline under the guidance of human expertise, even automating the flow between some of these steps.
Thu, January 29, 2026 12:30 - 13:30 Room 1008
Title: Surviving RAMageddon: From Bottlenecks to Breakthroughs
RAMageddonを生き抜く:ボトルネックからブレイクスルー(日本語通訳あり)
- Speaker
-

- Martin W Hiegl
- Executive Director, Enterprise AI & HPC, ISG ESMB Segment & AI
- Biography
- Martin W Hiegl is Executive Director and General Manager responsible for the Lenovo HPC Solution Business. He is leading an expert team spanning from Sales over Product and Development to Service and Support to be the client’s most trusted partner in HPC Infrastructure Solutions.
Based in Stuttgart, Germany, Martin has been passionate about helping clients tackle humanities greatest challenges and driving innovation in HPC solutions for 20 years. The adoption of AI empowering customer’s Intelligent Transformation is the latest evolution in this journey.
Before transferring to Lenovo, Martin held HPC and Public Sector Sales management positions at IBM. He has a Diplom (DH) from DHBW, Stuttgart, as well as a Bachelor of Arts (Hons) from Open University, London, in Business Informatics and holds a US patent related to serial computer expansion bus connection.
When not immersed in HPC Martin loves to spend time with his family and continues to relentlessly pursue the rehabilitation of the German sense of humour.

- John Josephakis
- Global VP of Sales and Business Development for HPC/Supercomputing, NVIDIA
- Biography
- John Josephakis is Global VP of Sales and Business Development for HPC/Supercomputing at NVIDIA. He has more than 20 years’ experience in high performance computing with a career that started in the labs at the US Department of Energy. Prior to NVIDIA, he ran sales and operations for Cray.
He holds a bachelor’s degree in economics and mechanical engineering from the University of Texas and an MBA from Saint Edwards University.Thu, January 29, 2026 12:30 - 13:30 12F Conference Hall
Title: Accelerating Research and Discovery with Google Cloud GPUs: Featuring SyntheticGestalt's AI Workloads
Speaker 1: Kei Hoshino, Google Cloud, Customer Engineer
Speaker 2: Kotaro Kamiya, SyntheticGestalt, CTO
Thu, January 29, 2026 13:30 - 15:00 Room 1102
Contributors: Mohamed Wahib (RIKEN R-CCS), Aleksandr Drozd (RIKEN R-CCS)
Abstract: As Fugaku reaches the midpoint of its operational lifetime, the system continues to evolve in both capability and impact across a diverse range of scientific domains. This focus session brings together users who have been working with Fugaku since its early days, offering a ground-level view of how the system has matured, what has been learned, and where user needs are heading. Through three complementary talks, the session will highlight practical experiences in large-scale application development, performance optimization, workflow evolution, and the integration of emerging technologies within the Fugaku ecosystem. Speakers will discuss both successes and challenges encountered in real-world scientific campaigns, providing insight into how user priorities have shifted as workloads grow in scale and complexity. The session aims to articulate a user-driven perspective on Fugaku’s mid-life stage, reflecting on the system’s unique capabilities while identifying areas where future enhancements could further accelerate scientific discovery. Attendees will gain an understanding of how the community is leveraging Fugaku today and what lessons can guide the next phase of high-performance computing in Japan and beyond.
Program:
- 13:30-14:00
- "Fugaku Operations: The First Five Years and the Road Ahead"
- Fumiyoshi Shoji (RIKEN R-CCS)
- 14:00-14:30
- "Optimizing Collective Communication on Torus Networks using Bine Trees”
- De Sensi Daniele (Sapienza University of Rome)
- 14:30-15:00
- "Experiences in Using Supercomputer Fugaku for Chemistry"
- William Dawson (RIKEN R-CCS)
Thu, January 29, 2026 13:30 - 17:00 12F Conference Hall
Contributors: Pedro Valero Lara, William F. Godoy, Dhabaleswar K. Panda
Abstract: This workshop objectives are focused on LLMs advances for any HPC major priority and challenge with the aims to define and discuss the fundamentals of LLMs for HPC-specific tasks, including but not limited to hardware design, compilation, parallel programming models and runtimes, application development, enabling LLM technologies to have more autonomous decision-making about the efficient use of HPC. This workshop aims to provide a forum to discuss new and emerging solutions to address these important challenges towards an AI-assisted HPC era.
Website: https://ornl.github.io/events/llm4hpcasia2026/
Call for Papers: Please see the website for details
Program:
- 13:30-13:45
- Welcoming and Introduction
- Pedro Valero-Lara (ORNL)
- 13:45-14:30
- Keynote: Updates on the Development of Japanese LLMs
- Rio Yokota (Institute of Science Tokyo)
- 14:30-15:00
- Paper talk: Evaluating Claude Code’s Coding and Test Au-tomation for GPU Acceleration of a Legacy Fortran Application: A GeoFEM Case Study
- Tetsuya Hoshino (Nagoya University)
- 15:00-15:30
- Break
- 15:30-16:10
- Invited talk: High performance communication library and transport for LLM training at 100K+ Scale
- Min Si (Facebook AI)
- 16:10-16:30
- Paper talk: Runtime Prediction for Local Deployment of Large Language Models: A Case Study on Qwen Models Covering LoRA Fine-Tuning, RAG, and Inference
- Jian Guo (Xi’an Uni-versity of Finance and Economics)
- 16:30-16:50
- Paper talk: Semantic Equivalence Verification of HPC Codes Using LLMs
- Yuta Tanizawa(Tohoku University)
- 16:50-16:55
- Best paper award
- Pedro Valero-Lara (ORNL)
- 16:55-17:00
- Wrap-up
- Pedro Valero-Lara (ORNL)
Thu, January 29, 2026 13:30 - 17:00 Room 801
Contributors: Zhaobin Zhu, Ryoma Ohara, Radita Liem
Abstract: AI and data-intensive workloads are driving up both computational and energy demands, with data movement and storage now consuming energy on par with computation. Yet, these costs remain poorly understood and rarely optimized. This workshop brings together researchers and practitioners from AI, HPC, and energy domains to address the challenges of modeling, profiling, and optimizing data flows for performance and sustainability. Topics include power profiling, bottleneck analysis, and energy-aware strategies across diverse architectures, from high-end HPC to resource-constrained systems. The workshop emphasizes holistic energy optimization, highlighting data movement as a critical factor in application performance and sustainability. It encourages the development of methods and tools that improve energy efficiency and supports collaboration toward more sustainable computing practices.
Website: https://dream-workshop.github.io
Call for Papers: Please see the website for details
Program:
- 13:30-13:35
- Opening Remarks
- 13:35-14:20
- Keynote
- Michela Taufer (The University of Tennessee)
- 14:20-15:00
- Invited Talk
- Kento Sato (RIKEN R-CCS)
- 15:00-15:30
- Break
- 15:30-15:47
- Fine-Tuned Sentence-BERT for HPC Job Outcome Prediction via Textual Feature Embedding
- Thanh Hoang Le Hai, Huy Nguyen Tuan, Bao Tran Dang, Bao Vo Thuong and Nam Thoai (Ho Chi Minh City University of Technology, Vietnam National University Ho Chi Minh City)
- 15:47-16:04
- Sustainable Power Reduction for DRAM applying Adaptive Stream-based Entropy Coding focusing on Video Processing System
- Taku Nishikawa, Koichi Marumo and Shinichi Yamagiwa (University of Tsukuba)
- 16:04-16:21
- Exploring I/O Performance and Power Consumption Trade-offs in Production Environments
- Zhaobin Zhu, Andreas Henkel and Sarah Neuwirth (Johannes Gutenberg University Mainz)
- 16:21-16:38
- A Co-Simulation Framework for Building Energy Management as a Testbed for Energy-Aware Data Movement Analysis
- Chomphunuch Wongphong, Patchararat Wongta and Worawan Marurngsith (Thammasat University)
- 16:38-16:55
- Quantifying the Energy Cost of Performance Inefficiency in HPC Applications
- Radita Liem and Dlyaver Djebarov (RWTH Aachen University)
- 16:55-17:00
- Closing Remarks
Thu, January 29, 2026 13:30 - 17:00 Room 1008
Contributors: Hiroshi Horii, Antonio Córcoles
Abstract: Quantum computing has the potential to elevate heterogeneous high-performance computers to be able to tackle problems that are intractable for purely classical supercomputers. This requires the integration of quantum processing units (QPUs) into a heterogeneous classical compute infrastructure, which we refer to as the quantum-centric supercomputing (QCSC) model. Achieving this requires multiple industries to work together and align their efforts to integrate the hardware and software, alike.
In this workshop we will present state-of-the-art solutions that are used in today’s heterogeneous compute architecture. We will demonstrate how QPUs are integrated into the existing frameworks without having to reinvent already established high-performance computing ecosystem tools and we will showcase how hybrid quantum-classical algorithms and applications can directly benefit from such QCSC architectures. Taken all together we discuss how these interdisciplinary integration efforts pave the way to quantum advantage becoming a reality in the near future.
Website: https://large-scale-quantum-classical-computing.github.io/asia-pacific/index.html
This session has been cancelled due to unavoidable circumstances.
Thu, January 29, 2026 13:30 - 17:00 Room 804
Room 802Contributors: Rossen Apostolov, Manoj Khare
Abstract: TBA
Thu, January 29, 2026 13:30 - 17:00 Room 802
Room 1202Contributors: Rossen Apostolov, Andrew Rohl, Michael Sullivan, Kengo Nakajima, Manoj Khare, Min-ho SUH
Abstract: TBA
Thu, January 29, 2026 13:30 - 17:00 Room 805
Contributors: François Mazen (Kitware), Jorji Nonaka (RIKEN R-CCS), Thomas Theußl (Consivi KG)
Abstract: First International Workshop on High Performance Massive Data Visualization.
Numerical simulations at large scale, nowadays up to exascale, tend to produce very large datasets which are very challenging to analyse and visualize. The current state of the art involves in situ and in transit techniques to analyse on-the-fly data and avoiding costly data saving on disk. In addition, emerging approaches leverage progressive analyses at the data loading stage and at the analysis stage.
This workshop proposes to explore current and novel approaches to post-process massive data, usually in high performance manners, generated from HPC systems (e.g. large-scale simulation results) and facilities (e.g. log data from the HPC system itself and its electrical and cooling facilities) as well as sensor data from different kinds of measurement systems: Parallel and distributed visualization
- Progressive analysis
- situ and in transit analysis and visualization
- ML-based large data visualization and analysis
- Large Scale Digital Twins
This workshop encourages contributed talks of recent work regarding methods, workflow, results, post-mortem of large scale data analysis, including in situ and in transit visualization. Ultimately, this workshop would connect the Asian HPC community with the international community working on large data visualization challenges and would share the existing and emerging solutions.
Website: https://hpmdv-9b1629.gitlab.io/
Program:
- 13:30-13:45
- Introduction
- François Mazen (Kitware), Jorji Nonaka (RIKEN R-CCS), Thomas Theußl (Consivi KG)
- 13:45-14:15
- Big Data Visualizations: challenges, solutions, and short-comings
- Jean Favre (CSCS)
- 14:15-14:45
- Case Study of In-Situ/In-Transit Visualization Using JAXA's In-House CFD Solvers
- Takanori Haga (JAXA)
- 14:45-15:00
- Update on In Situ and In Transit Visualization with ParaView Catalyst
- François Mazen (Kitware)
- 15:00-15:30
- Break
- 15:30-16:00
- xR-Enabled In-Situ Steering of CFD Simulations Using Particle-based Visualization
- Takuma Kawamura (JAEA)
- 16:00-16:30
- Handling I/O bottlenecks using in-situ data analysis with PDI and Deisa.
- Benoît Martin (CEA)
- 16:30-16:45
- Panel discussion: challenges and future
- Workshop chairs and all attendees
- 16:45-17:00
- Closing remarks
- François Mazen (Kitware), Jorji Nonaka (RIKEN R-CCS), Thomas Theußl (Consivi KG)
Thu, January 29, 2026 13:30 - 17:00 Room 1006
Contributors: Justin Wozniak, Nicholas Schwarz, Hannah Paraga
Abstract: Experimental science areas are increasingly adopting advanced computing techniques. From established institutional computing solutions to highly customized approaches, diverse scientific areas of research use myriad approaches to computing and automation. There is a great opportunity for idea sharing and collaboration on the common aspects to managing the intersection of experiment and computation.
Advances in machine learning (ML) and artificial intelligence (AI) capabilities are on the verge of accelerating discovery far beyond traditional workflows. Improvements in the numerical engines, simulations, digital twins, and agentic AI could transform experimental science by autonomously designing, executing, and adapting experiments in real time. Additionally, integration of advanced computing resources with data management and experiment control systems supports these transformations. However, challenges remain. Automated services that manage all aspects of the scientific work cycle have not yet been realized due to the complexities of collecting physical data, managing the data lifecycle, actuating computation, and interacting with human users.
The ACX Workshop will be an exciting forum for the exchange of ideas around this topic. We invite researchers and developers of inspiring results in “big science” endeavors, to the “day one” creativity that it takes to bring automation into emerging and potentially transformational experimental approaches.Website: https://acx-2026.cels.anl.gov/
Call for Papers: https://acx-2026.cels.anl.gov/call-for-papers/
Program:
- 13:30-13:45
- Introduction
- Workshop Chairs (Argonne National Laboratory)
- 13:45-14:10
- Python-based Workflow System for Quantum-HPC Hybrid Application on HPC System and Quantum Computer with Shared Network
- Soratouch Pornmaneerattanatri (RIKEN Center for Computational Science)
- 14:10-14:35
- The LCLStream Ecosystem for Multi-Institutional Dataset Exploration
- David Rogers (Oak Ridge National Laboratory)
- 14:35-15:00
- Beyond Centralized Labs: Federating the Co-Scientist
- Amal Gueroudji (Argonne National Laboratory)
- 15:00-15:30
- Break
- 15:30-15:55
- xspline3d: A Python Library for MPI-Based Spline Interpolation Enforcing Global Continuity in Distributed 3D Volumes
- Wenyang Zhao (RIKEN Center for Computational Science)
- 15:55-16:20
- Performance and Programmability of MPI+X Integration with CUDA, HIP, SYCL, OpenACC, and OpenMP Offloading for Supercomputing: A Case Study on Dense Matrix–Vector Multiplication
- Ezhilmathi Krishnasamy (University of Luxembourg/University of Ljubljana)
- 16:20-16:50
- Invited Talk: “Computing for Light Source-Driven Science: Data, Workflows, and AI at the Advanced Photon Source”
- Alec Sandy (Argonne National Laboratory)
- 16:50-17:00
- Awards
- Workshop Chairs (Argonne National Laboratory)
Thu, January 29, 2026 13:30 - 17:00 Room 702
Contributors: Edgar A. Leon (Lawrence Livermore National Laboratory (LLNL))
Abstract: Modern supercomputing has reached a critical juncture where raw computational power alone cannot guarantee optimal application performance. As the world's most powerful systems—including Frontier (the first exascale computer) and El Capitan (currently the fastest supercomputer)—feature increasingly complex heterogeneous architectures with over a million cores, tens of thousands of accelerators, and intricate memory hierarchies, the challenge of efficiently mapping applications to hardware has become paramount.
This half-day tutorial addresses the often-overlooked third pillar of high-performance computing: Affinity—the strategic mapping of software (first pillar) to hardware resources (second pillar). While most HPC practitioners focus on algorithmic optimization and hardware capabilities, failing to account for hardware locality creates expensive data movement that can cripple even well-designed applications on top-tier systems.
What you will learn: (1) Discover and navigate complex hardware topologies using industry-standard tools like hwloc; (2) Master both policy-driven (high-level) and resource-specific (low-level) affinity techniques; (3) Control process and GPU kernel placement using Slurm and Flux resource managers; (4) Leverage hardware locality to minimize data movement and maximize performance; and (5) Apply locality-aware mapping strategies that scale from small clusters to exascale systems.
Hands-on experience: Through progressive modules and practical exercises on a live cluster environment, attendees will work with architectures from the world's leading supercomputers. The tutorial builds from fundamental topology discovery to advanced multi-GPU affinity policies, ensuring both beginners and intermediate users gain valuable skills.
Target audience: HPC users, computational scientists, students, and center staff seeking to bridge the gap between applications and hardware. No prior affinity experience required—just basic Linux knowledge and familiarity with parallel programming concepts.
Transform your understanding of HPC performance optimization and unlock your applications' full potential on today's most complex computing systems.Website: https://github.com/LLNL/mpibind/blob/master/tutorials/sca26/README.md
Thu, January 29, 2026 13:30 - 17:00 Room 1004-1005
Contributors: Nicholas Jones and David Allen (Los Alamos National Lab (LANL))
Abstract: This tutorial will introduce the fundamentals of cloud-like system provisioning with OpenCHAMI and enable attendees to build on what they’ve learned by applying DevOps principles to manage OpenCHAMI clusters.
OpenCHAMI is a relatively new open source, open governance project from partners: HPE, the University of Bristol, CSCS, NERSC, and LANL. It securely provisions and manages on-premise HPC nodes at any scale. With a cloud-like composable microservice architecture, and an emphasis on infrastructure as code, the tools to install and manage OpenCHAMI may not be familiar to many traditional HPC administrators. Having helped our own teams at LANL to make this transition, the presenters want to bring the same training to a broader audience.
In this half-day tutorial, attendees will learn how each of the components in an OpenCHAMI system can be used to bootstrap their own virtual clusters in the first hour and then build on what they’ve learned to leverage DevOps workflows to automate the management of multiple clusters.This session has been cancelled due to unavoidable circumstances.
Thu, January 29, 2026 13:30 - 17:00 Room 1009
Contributors: Tyler Takeshita, Sebastian Stern, Benchen Huang, and Jin-Sung Kim
Abstract: Real-world quantum systems are subject to external interactions, no matter these interactions being intentional or unintentional. Efficient and accurate numerical simulation of open quantum systems (OQS), therefore, provide valuable insights into fundamental quantum processes responsible for experimental observations. Accurate simulations of OQSs are a crucial tool in designing higher performance quantum processors, enabling researchers to explore and optimize the vast parameter space of quantum hardware, uncover fundamental physics enabling higher performance qubits, and design higher fidelity control and readout methods. However, the computational demand of these simulations grows rapidly due to the exponentially increasing dimensionality of the Hilbert space and can require the use of high-performance compute (HPC) environments. In this tutorial, we demonstrate how to develop, test, and scale the simulations of OQS on AWS using CUDA-Q Dynamics and QuTiP, both accelerated by cuQuantum. The tutorial introduces open quantum dynamics basics and their computational considerations, independent of the underlying cloud architecture. During hands-on labs, we then architect cloud-native HPC solutions capable of leveraging accelerated compute resources, like Amazon EC2 P6 instances powered by NVIDIA Blackwell GPUs. Participants will get free access to temporary AWS accounts so they can provision their own HPC cluster during the tutorial. All attendees leave with code examples they can use as a foundation for their own projects.
Thu, January 29, 2026 13:30 - 17:00 Room 1001
Contributors: Julien Loiseau, Ben Bergen, Scott Pakin, and Davis Herring
Abstract: FleCSI is a C++ library that simplifies the development of portable, scalable scientific computing applications. It provides a distributed, a task-parallel programming model that abstracts away the complexity of parallelism, data management, and execution across architectures. By managing inter-process communication and synchronization on behalf of the application, FleCSI protects developers from common pitfalls such as race conditions and deadlocks. It also coordinates data movement between CPUs and GPUs, ensuring that GPU kernels receive data in a form that is optimized for data-parallel computation. This tutorial will be the first public hands-on session for FleCSI. Participants will learn the core programming models that make FleCSI unique: the Control Model for defining control-flow logic, the Data Model for managing distributed fields and topologies, and the Execution Model for running parallel tasks. The session will emphasize building real-world HPC applications, including demonstrations of on-node parallelism, tasks, and specialization mechanisms. The tutorial includes live coding exercises that guide attendees in developing a scalable FleCSI application from a serial example. By the end of the session, participants will be equipped to create their own performance-portable HPC applications using FleCSI’s abstractions. FleCSI is actively used in research applications such as FleCSPH and HARD, showcasing its applicability in astrophysics, multiphysics simulations, and radiation hydrodynamics. Its open-source nature makes it an attractive choice for research teams building future-proof applications on emerging architectures.
Website: https://flecsi.github.io/training/
This session has been cancelled due to unavoidable circumstances.
Thu, January 29, 2026 13:30 - 17:00 Room 1202
Room 1008Contributors: Philip W. Fackler and Pedro Valero-Lara
Abstract: The Julia for performance-portable High-Performance Computing (HPC) via JACC tutorial offers attendees a hands-on opportunity to gain practical experience in leveraging Julia for efficient and parallel code development tailored to their HPC requirements. JACC is a Julia library that enables a single code to be easily parallelized across CPUs and GPUs: NVIDIA, AMD, Intel, Apple and can interoperate with the Julia HPC ecosystem in particular with the message passing interface (MPI). Due to the recent adoption of Julia across several scientific codes for its productive ecosystem (scientific syntax, packaging, analysis, AI) and performance via LLVM compilation, hence we address the need for vendor-neutral HPC capabilities. Similar tutorials have been offered at several venues: SC24, ICPP25, and the US Department of Energy labs and supercomputing facilities. During the proposed 3 hours we will cover basic aspects of the Julia language and provide exercises and a full application (Gray-Scott) to showcase the use of JACC APIs with MPI and parallel I/O (via ADIOS) in a real scientific problem. The tutorial targets scientists with interest in Julia at a beginner and intermediate level on the use of parallel code at a minimal cost.
Website: https://github.com/JuliaORNL/julia-hpc-tutorial-hpcasia26
Thu, January 29, 2026 13:30 - 18:30 Room 1007
Contributors: Filippo Spiga, Gabriel Noaje, Naruhiko Tan, Norihisa Fujita, Miwako Tsuji, Takashi Shimokawabe, and Shinnosuke Furuya
Abstract: Arm technology has become a compelling choice for HPC due to its promise of efficiency, density, scalability, and broad software ecosystem support. Arm expansion in the datacenter started in 2018 with Arm Neoverse, a set of infrastructure CPU IPs designed for high-end computing. The Arm-based Fugaku supercomputer, first of its kind implementing Arm SVE instruction set, entered the Top 500 in June 2020 scoring at the top and retaining a leadership position over the years not only in HPL but also for HPCG. There is a growing interest in diversifying and exploring new computing architectures to re-create a vibrant and diverse ecosystem as it was more than a decade ago. Arm technology is at the forefront of this wave of change. To further advance datacenter and accelerated computing solutions, NVIDIA has built the Grace Hopper Superchip which brings together the groundbreaking performance of the NVIDIA Hopper GPU with the versatility of the NVIDIA Grace CPU, tightly connected with a high bandwidth and memory coherent Chip-2-Chip (C2C) interconnect. The NVIDIA Grace CPU packs 72 high performance Armv9 cores on a single die to realize competitive FP64 TFlops of computing performance and up to 500GB/s of memory bandwidth at industry-leading power efficiency. In this tutorial, our experts will answer any questions you may have about fully unlocking the scientific computing potential of the Grace CPU and Grace Hopper GH200 Superchip. The speakers will guide the attendees through compile, execute, profile and optimize HPC and AI workloads for Arm to demystify those claims that changing CPU architecture is hard. At the same time it will introduce how to leverage the GH200 unique architecture using multiple programming models thanks to practical examples attendees can replicate. Remote access to NVIDIA GH200 resources will be provided.
Website: https://www.jcahpc.jp/event/SCA_HPCAsia2026_Tutorial.html
Registration form: https://forms.gle/5H169bneuC1dFUNv9 (MANDATORY — deadline December 21st)